
Remember me

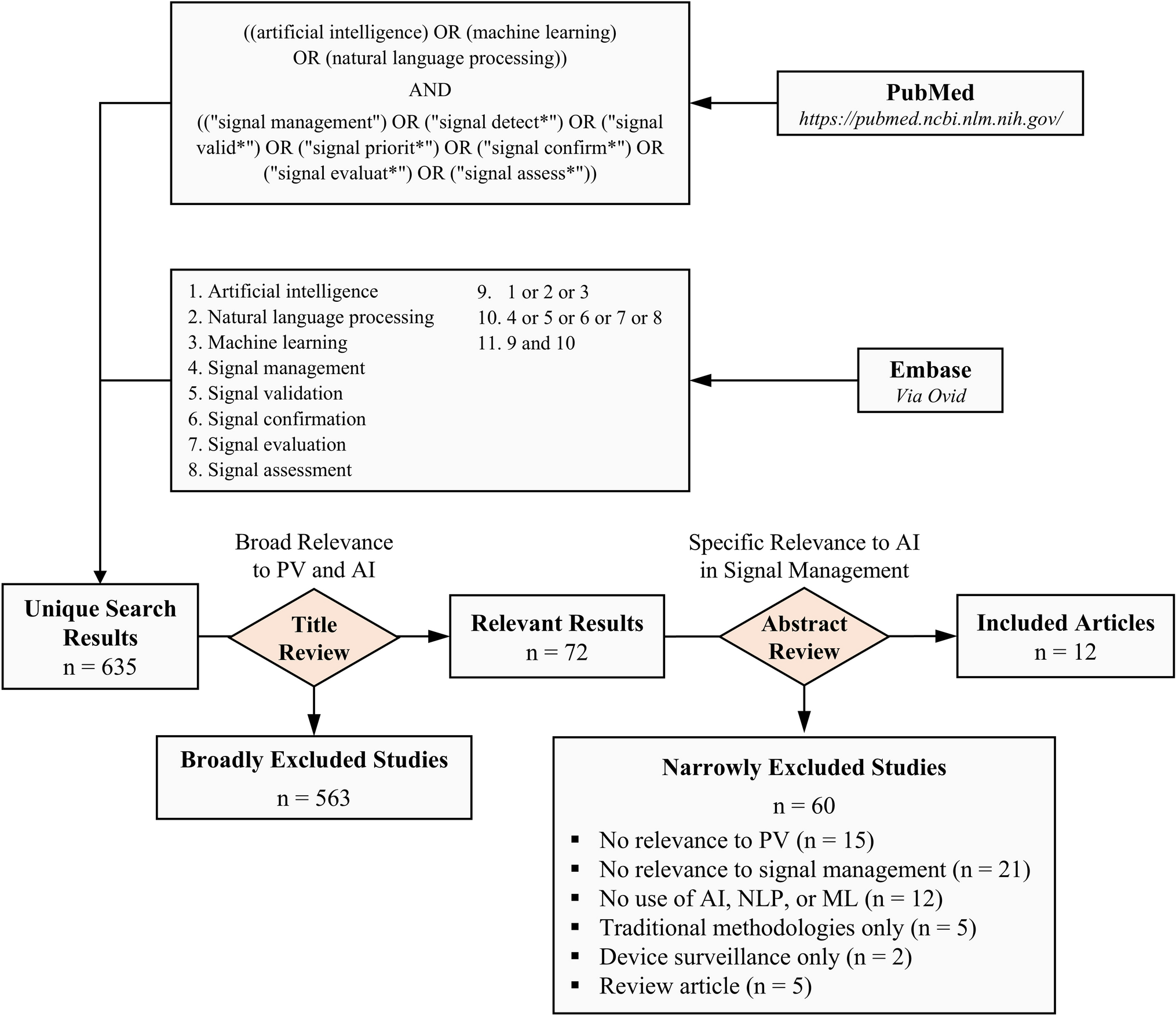


This was a proof-of-concept study designed to evaluate the feasibility, accuracy and speed of using GenAI to extract PICO data from abstracts of randomised clinical trials. Figure 1 provides an overview of the full methodology.
Fig. 1
Summary of the PICO extraction process using GPT-4o. PICO, population, intervention, comparator, outcome; GPT-4o, Generative Pre-trained Transformer 4 Omni. *A random sample of 350 abstracts was selected for human validation
2.1 Search StrategyRelevant abstracts were identified using the PubMed database, which was chosen due to its freely available application programming interface (API). An API is a set of rules or protocols that allows different software applications and systems to exchange data, features and functionality with each other [14, 15]. On 11 June 2024, the search API was used to retrieve a list of unique IDs [PubMed identifiers (PMIDs)] for clinical trial abstracts using the following search string: (“randomized controlled trial”[Publication Type] OR (“randomized”[Title/Abstract] AND “controlled”[Title/Abstract] AND “trial”[Title/Abstract])) NOT (“animals”[MeSH Terms] NOT “humans”[MeSH Terms]). The PubMed ‘specific/narrow’ therapy category filter, which has a sensitivity of 93% and specificity of 97% for capturing all clinical trials, was applied to streamline the results and make them more manageable (i.e. ≈700K versus 6 million results) [16].
All retrieved PMIDs were used to locate the corresponding abstracts within a local copy of the PubMed database, which is available for download. All abstracts were included in the analysis; no further filters were applied. Once retrieved, the abstracts were stored on a local hard drive for interaction with the LLM.
2.2 LLM and API Implementation for PICO ExtractionGenerative Pre-trained Transformer 4 Omni (GPT-4o) was selected as the LLM engine for the analysis. In June 2024, GPT-4o was recognised as a leading LLM, consistently ranking at the top of prominent leaderboards [17, 18]. Although these leaderboards do not specifically evaluate PICO extraction capabilities, they assess LLMs across a range of metrics that can be considered proxies for human intelligence. GPT-4o was chosen not only for its status as a frontrunner in simulating intelligence but also for its accessibility via both API and batch API, which was needed for handling the volume of the analysis.
PICOs were extracted using the OpenAI Batch API, which enabled parallel processing of the abstracts by breaking them into “chunks” [19]. This method was ideal because the extraction of PICOs was identified as an “embarrassingly parallel” problem. In computing, “embarrassingly parallel” refers to a type of problem or algorithm that can be easily separated into many discrete, independent tasks that can be executed simultaneously with minimal or no need for communication between the tasks [20]. In this case, just as multiple humans could independently review many abstracts using the same criteria without needing to coordinate with each other, multiple processes running on multiple computers and/or servers can follow the same procedure simultaneously, scaling up easily and cheaply to thousands of instances.
In addition to speeding up the process through parallel processing, the batch API significantly reduced code complexity by greatly mitigating the need to manage timeouts and API rate-limiting compared with processing abstracts individually [19, 21]. Timeouts occur when an API takes too long to respond [21], and rate limiting restricts the number of requests that can be made in a given time period [22]; both of these can disrupt processing workflows. While each batch is guaranteed to finish within 24 h, there is a possibility that some individual elements might fail or be skipped [21]. However, in practice, all of our batches completed without issue, typically in less than 2 h, even when many were launched simultaneously. The batch API’s status report tracks errors and skipped queries, which would have allowed us to identify and retry an operation or batch if necessary. However, in our case, every operation in every batch was successfully processed [19, 21]. A final advantage of using the batch API was a 50% cost reduction compared with processing abstracts individually [19, 21].
2.3 Prompting StrategyInteraction with GPT-4o was facilitated via API calls executed through a Python script, using custom prompts developed specifically to guide extraction of the necessary PICO data from the collected abstracts. The process began with simple input/output (I/O) zero-shot prompting [23], where the LLM was provided with an abstract and asked to extract each PICO element. Zero-shot prompting is a technique where the LLM is asked to perform a task or solve a problem that it has not been explicitly trained on, without any illustrative examples or guidance [24,25,26]. I/O zero-shot prompting was chosen because no complex logic or instructions were required for the LLM to complete the extraction. In our experience, extracting and summarising information that is already present in text is a task that LLMs excel at [7]. For example, to extract the population data, the prompt might read: “From the medical abstract below, please extract information pertaining to the patients being studied, including disease, line of therapy and disease severity; be detailed in your answer” (Fig. 2).
Fig. 2
Example Python code for extraction of the population of interest for one abstract
The outputs from initial prompts were reviewed, and the prompts were then refined and resubmitted for further evaluation. This iterative process of reviewing outputs and refining prompts continued until no further improvements were identified, resulting in the final, optimised set of prompts.
2.4 Accuracy of the PICO ExtractionsTo assess the accuracy of the PICO extraction, a random subsample of 350 abstracts was selected for human verification after the LLM completed the screening of all abstracts and the PICO extractions were considered final. The verification process involved confirming whether all PICOs were correctly identified. The sample of 350 abstracts, representing 0.05% of the total dataset, was considered an acceptable size within the study’s timeframe, and it exceeded the amount a reviewer could feasibly verify in a single working day. Additionally, accuracy served as a criterion for stopping. If the extraction had been highly inaccurate, verification would have continued until the reasons for inaccuracy were identified.
2.5 Time and Cost Analysis of the PICO ExtractionsTo evaluate the time savings of using GenAI for PICO extraction, we tracked the number of abstracts a human reviewer could process (i.e. comparing the PICOs extracted with the original abstract text) in 1 day. The total number of PICO abstract extractions processed by GenAI was then compared with human labour, assuming an 8-h working day and 250 working days per year (accounting for weekends and public holidays). The working days per year assumption is likely an underestimation, as it does not account for variations in vacation policies or potential sick leave.
The cost of using the OpenAI Batch API was compared with the cost of processing abstracts individually. Each operation performed using the OpenAI LLM incurs a token usage, which reflects the combined number of tokens in both the input query and the generated response. These token counts are provided in the metadata of each API response. OpenAI applies a token-based pricing structure, with charges varying by model. This pricing applies uniformly, whether queries are processed individually or in batches through the Batch API. For batch operations, OpenAI offers a 50% discount to promote the use of this method [19, 21]. Following batch processing, we aggregated the reported token counts to calculate the total token usage, which was then multiplied by the published model-specific token rate. The final cost was determined by applying the 50% discount to this calculated total.
2.6 PICO Extraction Data StorageThe final extracted PICO data were initially stored as CSV files and then imported into a PostgreSQL database. PostgreSQL is a leading relational database system known for its robust full-text search capabilities, offering ‘tsvector’ and ‘tsquery’ data types that optimise full-text search and query functions. It also provides a variety of other tools useful for full-text search, such as stemming, stop words and thesauri. An advantage of using PostgreSQL over a dedicated document database (e.g. Elasticsearch) is that it allows for complex queries combining traditional structured query language (SQL) database operations with full-text search. The PostgreSQL database was constructed via the following steps: (1) a PostgreSQL database was provisioned using the Amazon Web Services Relational Database Service (AWS RDS); (2) a database schema optimised for full-text search was designed; (3) data were uploaded using custom bulk insert operations written in Python.
Comments (0)