
Remember me
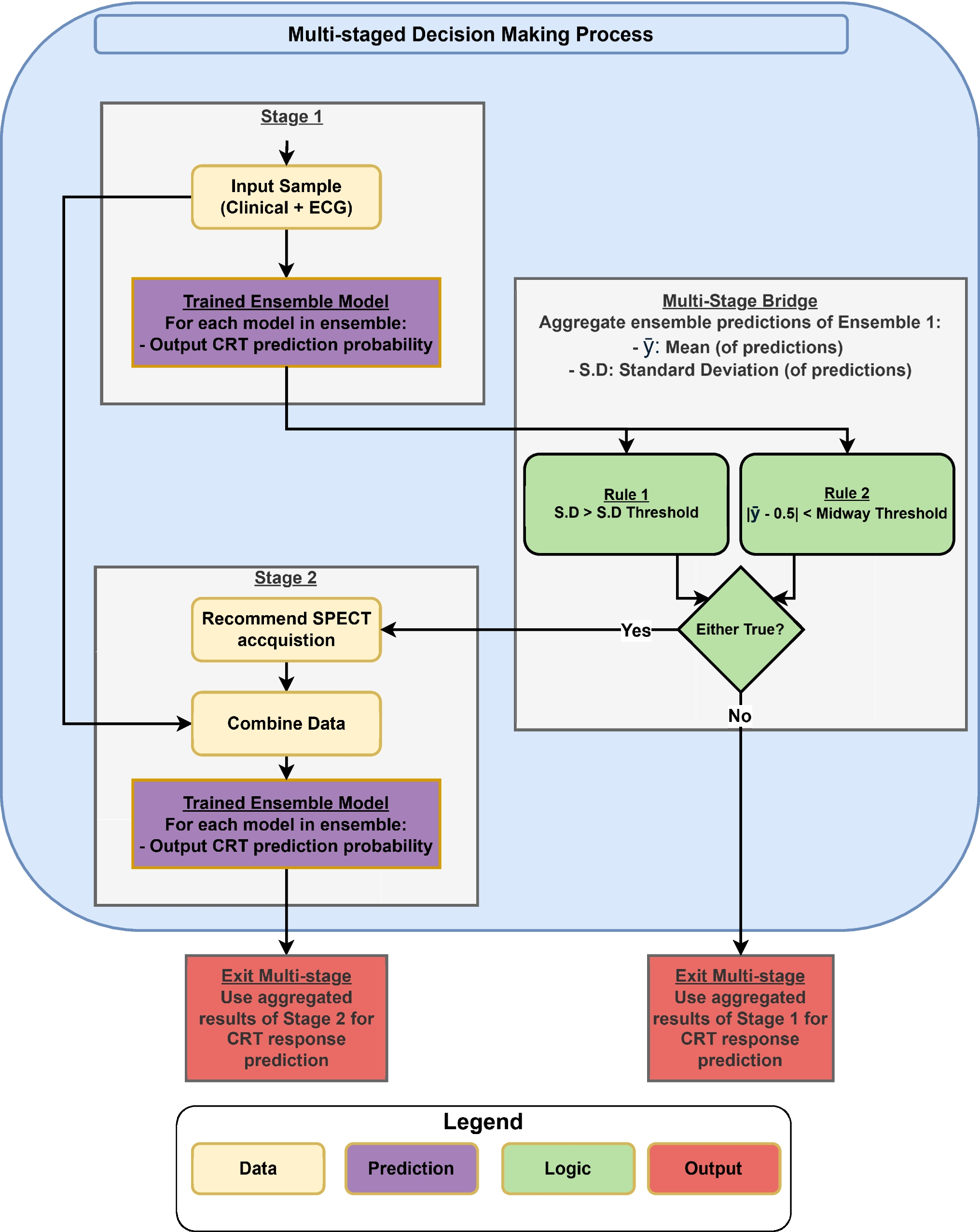

The proposed framework considers three keypoints located at specific sites of the larynx: the posterior angle of the left and right VF (LV and RV, respectively), and the anterior commissure (A), as shown in Fig. 1. The choice of these points is driven by clinical considerations, as the straight lines connecting LV/RV and A delineate the free border of the VF as changes in their position and movement can reveal information about VF angular movements, tension, and adjustments made during voice production.
Our model is inspired by the classical encoder-decoder architecture of U-Net [23]. We employed the MobileNetV2 architecture [24], pre-trained on ImageNet, as the U-Net encoder (\(e(\cdot )\)), which serves as a feature extractor, and a decoder network (\(d(\cdot )\)) to recover spatial information and regress heatmaps. We selected MobileNetV2 as (\(e(\cdot )\)) for its lightweight architecture and computational efficiency, which enable effective feature extraction while remaining suitable for deployment in resource-constrained settings like those in this study. The \(e(\cdot )\) is composed of an initial convolutional layer with 32 filters and a stride of 2, which reduces the image size by half, followed by batch normalization and ReLU activation. This initial layer is followed by a series of 17 inverted residual blocks, each consisting of an initial 1 \(\times \) 1 convolution followed by a 3 \(\times \) 3 depthwise convolution and ending with another 1 \(\times \) 1 convolution. At each block, the number of channels increases enabling the incremental learning of more complex features. The number of channels starts from 32 and progressively increases to 576. Similarly, the \(d(\cdot )\) is composed of four blocks, each comprising two 2D conv layers followed by batch normalization and ReLU activation. To recover the lost features resulting from the downsampling in the \(e(\cdot )\) path, the input of each block is concatenated with the corresponding feature maps from \(e(\cdot )\). The last block consists of three 2D conv layers, with the first two being followed by a ReLU activation function, and the last one activated by sigmoid. The proposed architecture is fed by stacking the endoscopic frames and the three corresponding heatmaps of size W \(\times \) H pixels. Each heatmap is represented by a Gaussian distribution centered at the keypoints center.
From the estimated coordinates of the three keypoints, the AGA is computed as follows:
$$\begin \text = \arctan (x_1 \times y_2 - y_1 \times x_2, x_1 \times x_2 + y_1 \times y_2) \end$$
(1)
where \((x_1, y_1)\) and \((x_2, y_2)\) represent the vector extending from A to LV, and the vector extending from A to RV, respectively.
The dataset used in this study consists of videoendoscopic frames of patients treated at the Unit of Otorhinolaryngology-Head and Neck Surgery, University of Brescia, Italy. Data were acquired using three different Olympus laryngoscopes (models ENF-VH, ENF-VQ, and ENF-V2), following the principles of the Helsinki Declaration, and approval was obtained by the local ethical committee. A total of 471 endoscopic images from 124 patients were collected from a dedicated archive and anonymized. Of these images, 114 were acquired from 28 subjects diagnosed with squamous cell carcinoma. The number of images per patient ranged from 1 to 5 with a median of 3, ensuring a comparable distribution of patient data.
Figure 1 shows some of the challenges in the dataset, including varying illumination levels, presence of both white-light and narrow-band frames, presence of noise, blurring and specular reflection, varying pose of the VF and different fields of view, and frames from pathological subjects. Another challenge in the dataset is related to the AGA variability, which has a median value of \(15.12^\), with first quartile (Q1)=8.09 and third quartile (Q3)=22.19, and an interquartile range (IQR)=14.10 (minimum AGA value=\(1.32^\), maximum AGA value=\(91.85^\)).
Frames annotation was performed using Label-studioFootnote 1 by an expert laryngologist with more than ten years of experience. The keypoints were assigned with visibility flags according to the COCO Keypoint detection annotation format: 0 for keypoints not present in the image (which do not occur in our dataset), 1 for keypoints present in the image but not visible (possibly occluded by other anatomical structures), and 2 for clearly visible keypoints.
Experimental ProtocolAll frames were downsampled from their original resolution of 640 \(\times \) 480 pixels to 224 \(\times \) 224 pixels, and mean intensity was removed from each frame. The ground-truth heatmap was generated by applying a Gaussian function centered at each annotated keypoint, with the intensity of each pixel computed based on its Euclidean distance from the keypoint using the following formula, with \(\sigma \) set equal to 20:
$$\begin f(x,y) = e^})^2 + (y - y_})^2}} \end$$
(2)
The model was trained for a maximum of 200 epochs with early stopping based on validation loss. Training was stopped if the validation loss did not improve for 10 consecutive epochs. Training optimization was performed using the Adam optimizer, with an initial learning rate of 0.001 and a batch size of 8, and a weighted mean squared error (W-MSE) loss \(\mathcal \), defined as follows:
$$\begin \mathcal = \sum _^ \left( w_i \cdot \frac \sum _^ (y_, j, i} - y_, j, i})^2 \right) \end$$
(3)
where \( y_, j, i} \) represents the true value of the \( j \)-th sample in the \( i \)-th channel, \( y_, j, i} \) denotes the predicted value of the \( j \)-th sample in the \( i \)-th channel, \( w_i \) is the weighting factor for the \( i \)-th channel, \( N \) is the total number of samples, and \( C \) is the total number of channels. The loss is computed by first calculating the squared differences between the true and predicted values for each channel, multiplying these differences by the respective channel weight, averaging these weighted squared differences for each channel, and then summing these averages across all channels to obtain the total loss. The weights used in this study are \(w_} = 1.2\), \(w_} = 1.2\), and \(w_} = 1.0\). The choice of these weights was guided by clinical considerations, emphasizing the importance of LV and RV in defining the free border of the VF. During training, on-the-fly data augmentation was performed to enhance generalization performance. The augmentation techniques included geometrical transformations such as horizontal and vertical flipping, and random rotation in the range of \(\pm 30^\), and intensity transformations such as random brightness correction in the range [\(-\)0.1, 0.1], random hue adjustment in the range [\(-\)0.2, 0.2], and random saturation in the range [0.5, 1.5]. These augmentations were randomly applied at each training iteration. To cope with the small amount of data, and to effectively use all the data available, we performed a five-fold cross-validation. For each fold, images were selected to ensure no patient overlap between the train and test sets. The best model among epochs is selected based on the lowest loss value obtained on the validation set. All the analyses were performed using Tensorflow 2.x on an NVIDIA RTX 2080 TI, with a Xeon e5 CPU and 128 GB RAM.
As ablation study, we investigated the influence of other loss functions on the training outcomes, including the standard mean squared error (MSE) loss and the weighted l1 loss in which the loss is weighted based on the proximity to a certain threshold. Additionally, we compared our framework against direct keypoint coordinate regression, to evaluate the performance differences between them and to demonstrate the advantages of using heatmap regression in terms of robustness in landmark detection. To this goal, we use the same backbone used for heatmap regression (i.e., MobileNetV2 pre-trained on ImageNet) which was followed by a custom regression head made of two separable convolution layers for keypoints coordinate regression. The model was trained using an MSE loss.
A further comparison with literature methods consists of the glottal area segmentation. The model used for this approach is the same as the one used in the proposed heatmap regression method described in the “Materials and Methods” section. In this case, the model is trained for segmentation using the endoscopic frame and the associated mask. The segmentation mask was constructed from the coordinates of the three keypoints: a triangle was formed by the three keypoints LV, A, and RV to define the glottal region mask, assigning to the pixels inside and outside the triangle the values of 1 and 0, respectively. The model was trained using the Dice (DSC) loss, defined as L = 1 - DSC, where DSC is the Dice similarity coefficient, defined as \(DSC = \frac\), where TP and FP are the true glottal area and background pixels detected as glottal area, respectively, while FN refers to glottal pixels that are segmented as background.
For a fair comparison, the ablation study and the comparison with the literature were performed using the same five-fold cross-validation, training setting, and computational hardware. To evaluate the performance of our framework for VF pose estimation and to compare it with the other tested models, we computed the root mean square error (RMSE) [pixels]. In the case of the heatmap regression model, the RMSE was calculated by comparing the coordinates of the ground-truth keypoints and the predicted coordinates, calculated by identifying the positions of the maximum activation value in the predicted heatmaps. In the case of the glottic segmentation model, the coordinates of the keypoints were obtained from the vertices of the smallest enclosing triangle that contains the predicted segmentation masks. The DSC was also used as a metric to further assess the segmentation model performance. All metrics were computed at the image level, ensuring an independent evaluation of each prediction.
Table 1 Results of the performance metrics computed on the test set of the five folds, and obtained from the proposed heatmaps regression model, the direct regression model, and the glottal segmentation modelFig. 2
Qualitative results obtained with the proposed framework on three randomly selected test frames. Blue boxes in the last column display close-ups of the (blue) predicted and (red) ground-truth keypoints
Fig. 3
Qualitative results from the comparison of all the tested models on three test samples. The improvements brought by the proposed heatmap regression model are particularly evident in the accurate positioning of the keypoints coordinates, even in more challenging cases, such as reduced glottic opening, or the presence of blur
Comments (0)