
Remember me

Our Institutional Review Board approved this retrospective study and waived the requirement for obtaining written informed consent from patients because of the retrospective study design.
DatasetsThe training, validation, and test datasets included contrast-enhanced chest and abdominal CT examinations conducted from April 1 to May 31, 2021, from April 1 to 11, 2022, and from April 1 to 18, 2023, respectively. In our hospital, many doctors are replaced on a yearly basis, leading to variations in clinical indications depending on the referring physician each year. This results in dataset variations across different years. By using a temporally independent dataset (i.e., three different years for the training, validation, and test datasets), we were able to evaluate the model’s performance in light of these variations and ensure its robustness [20]. Clinical indications, age, and anatomic coverage of the exams written in Japanese were collected from the Picture Archiving Communicating System and saved in CSV format. Of 3111, 570, and 956 radiology exam requests, 144, 40, and 6 were excluded due to inadequate or inappropriate clinical indications to assign protocols in the training, validation, and test datasets, respectively. We included only protocols with frequencies of at least 0.3%, narrowing them down to 12 protocols (Table 1), due to the rarity of protocols mainly used for research studies or uncommon clinical scenarios. This adjustment resulted in 2939, 523, and 941 requests for the training, validation, and test datasets, respectively. Cases where two protocols were assumed to be uniquely optimal were excluded from the training and validation datasets (110/25 cases) but included in the test dataset (55 cases) by accepting two true labels, to closely simulate the real-world tasks in the test dataset. Finally, the final training, validation, and test datasets consisted of 2829, 498, and 941 requests, respectively (Fig. 1). Table 2 shows the label frequency of each category in the training, validation, and test datasets.
Table 1 CT protocol classesFig. 1
Data selection for training, validation, and test dataset
Table 2 Patient background information and prevalence of each protocol in training, validation, and test datasetsReference StandardThe clinical indication section, age, and anatomic coverage of the exam were reviewed. Radiologist A, with imaging experience of 4 years, conducted these evaluations for the training and validation datasets. Radiologists A and B (with imaging experience of 6 years) established the reference standard for the test dataset. In cases of disagreement, the true label was determined by senior radiologist C, who has 14 years of imaging experience.
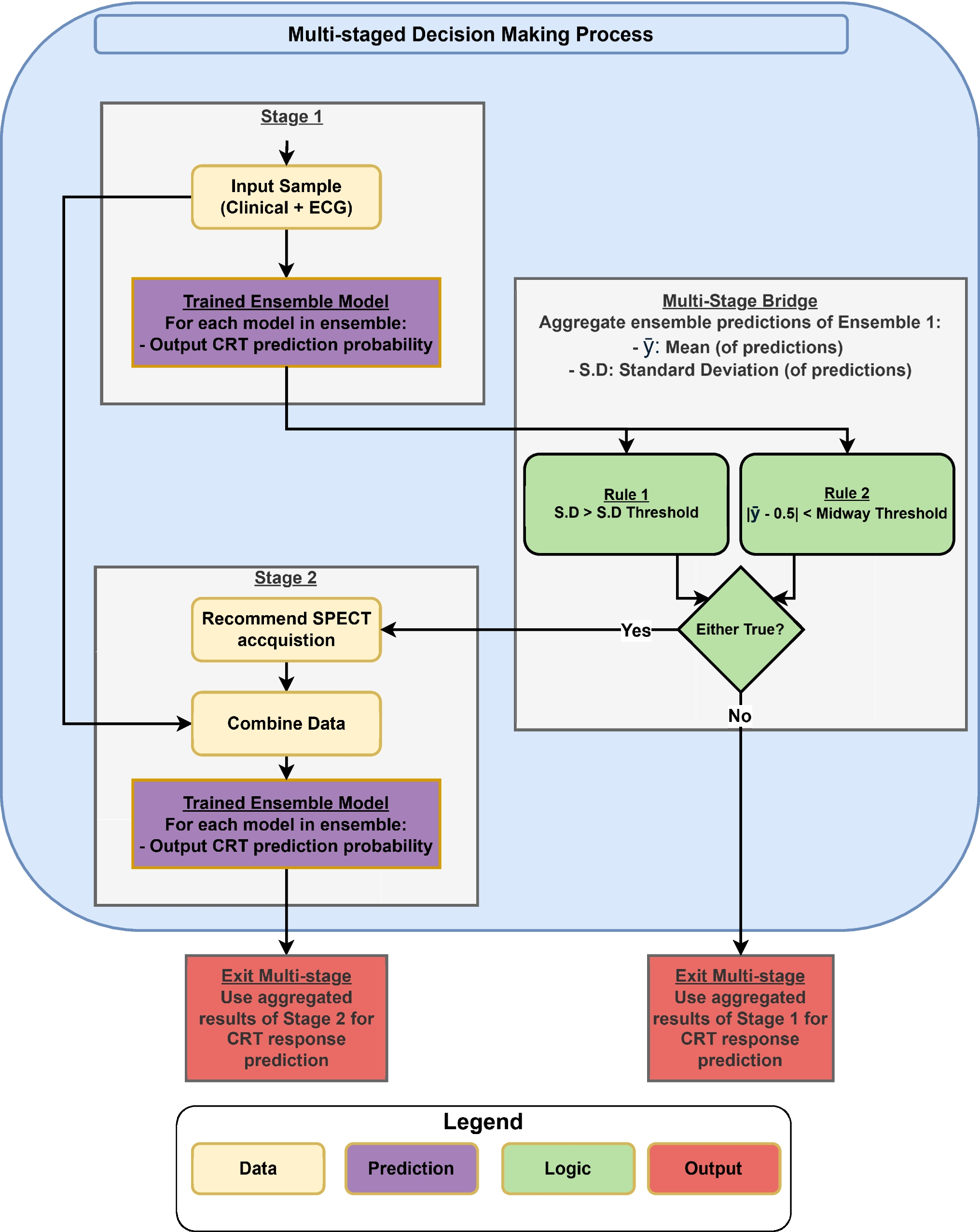
Fine-Tuning of the Pretrained LLMProgramming language of Python version 3.10.13 (https://www.python.org/) and Transformers library version 4.35.2 (https://huggingface.co/) on a workstation equipped with a central processing unit of Core™ i9-10980XE, a graphic processing unit of GeForce RTX™ 3060 (NVIDIA), and a random access memory of 64 GB were utilized for fine-tuning the pretrained BERT Japanese model (https://huggingface.co/cl-tohoku/bert-base-japanese). The model, including 12 layers, 768 hidden states dimensions, and 12 attention heads, was pretrained on the Japanese Wikipedia as of September 1, 2019. The text data was tokenized using the BERT tokenizer, converting the input into IDs, token type IDs, and attention masks. Input involved a single string concatenated from the sections of clinical indication, age, and anatomic coverage, categorized into 12 groups according to logits for each group (Fig. 2). Fine-tuning and validation were conducted in five sessions, each using a differently shuffled training dataset seed, with 15 epochs per session, to consider variability in fine-tuning results and select the best-performing model. We adjusted the loss function by setting the weight of each class proportional to the inverse of its prevalence in order to address class imbalance [21, 22]. Other hyperparameters were set and fixed at their default values as described in the Transformers library (https://huggingface.co/docs/transformers/main_classes/trainer). The model with the best macro sensitivity (calculated by averaging the sensitivities of each class with equal weight given to each class) in the validation dataset was saved and further assessed in the following session. The code used for fine-tuning is provided in the supplemental material.
Fig. 2
The process of fine-tuning a pre-trained large language model for CT protocol classification. The original dataset comprises patient age, anatomic coverage, and clinical indication, which are concatenated into single strings to serve as input data. Corresponding protocol assignments are used as labels for training. This combined dataset is fed into the pretrained language model, where fine-tuning updates its parameters to better suit the specific task. Finally, a task-specific classification head is attached to the fine-tuned model to generate prediction scores for each CT protocol based on the input data
Evaluation of the Fine-Tuned LLM in the Test DatasetThe best-performing model was examined on a randomly selected subset of 800 cases from the test dataset, which was also used in the subsequent evaluation section involving the radiologists. (The number was limited to 800 cases to mitigate reader fatigue, while the remaining 141 cases were allocated for practice sessions as described below.) The evaluation included reviewing time, weighted accuracy, and macro sensitivity.
Evaluation of the Fine-Tuned LLM as Clinical Decision Support SystemIn Japan, a 2-year clinical internship involves rotations across multiple specialties after graduation. Afterward, a 3-year radiology residency program is required, followed by 2 years of subspecialty fellowship training. Readers were recruited from two groups to assess the effect of fine-tuned LLM across different stages of training. The first group consisted of radiology residents in the residency program (readers 1 and 2, with a total of 2 years post-graduate experience, including 3 months of imaging experience, also known as “radiology resident”). The second group involved general radiologists in subspeciality fellowship training (readers 3 and 4, with a total of 5 years of post-graduate experience, including 3 years of imaging experience, referred to as “radiologists”).
The readers’ performance was categorized into the radiologists and radiology resident groups and then combined.
The cases per session were limited to 400 cases for each observer because too many samples and test duration caused the reader’s fatigue and deteriorated the quality of collected data. A total of 8 blocks (each containing 100 cases) were randomly selected (blocks A–H) from the 941 test datasets. Among the 4 observers, 1 radiologist and 1 radiology resident (readers 1 and 3) reviewed blocks A–D, whereas the other radiologist and radiology resident (readers 2 and 4) reviewed blocks E–H. To reduce bias, readers reviewed 200 and another 200 cases without and with the fine-tuned LLM, respectively, during one session and complementary cases during a second session so that each observer reviewed each case twice: once without and once with the fine-tuned LLM. The order of using assistance and non-assistance was alternated per block. A washout period of at least 2 weeks was set between the two sessions to minimize recall bias. A practice round was performed using the remaining cases with and without assistance before the main evaluation. Each reader was required to practice with and without assistance on at least 10 cases, with a maximum of 141 cases (Fig. 3). Observers were notified of the model’s performance on the validation dataset (not on the test dataset), including top-1 and top-2 accuracy and the confusion matrix.
Fig. 3
Schematic of observer performance test. From the 941 test datasets, 8 blocks (each containing 100 cases) were randomly selected (blocks A–H). Among the 4 observers, 1 radiologist and 1 radiology resident (readers 1 and 3) reviewed blocks A–D, whereas the other radiologist and radiology resident (readers 2 and 4) reviewed blocks E–H. Each observer reviewed each case twice over two reading sessions. The order of using assistance and non-assistance was changed per block. A washout period of at least 2 weeks was set between the two sessions. A practice round was performed using the remaining cases with and without assistance before the main evaluation
FileMaker Pro 18 Advanced (Claris International, Inc.) was used for the user interface to simulate a real-world input interface (Fig. 4). Only the clinical indication, age, and anatomic coverage of the requests were viewed, with 12 protocol choices provided, in the scenario without assistance from the fine-tuned LLM. Additionally, decision support information, specifically the top-1 and top-2 labels (class with the highest and the second-highest logits of the model’s output) from the fine-tuned LLM’s output, was provided for reference in the scenario with assistance. The labels assigned by the readers and their review times for each case were documented.
Fig. 4
The user interface is used for observer performance tests. The figure shows the scenario with the assistance of a large language model. The top-1 and top-2 labels from the fine-tuned LLM’s output are provided above the dropdown list of all 12 protocols. The reader accepts a protocol by pressing the “Adopt this protocol” button
Bad protocoling causes excessive or inadequate tests, resulting in unnecessary radiation exposure or failure to address the clinical question; thus, we evaluated the clinical effect of protocol errors. We reviewed each case and categorized them into the following groups: “optimal,” where the protocol agreed with the reference standard; “suboptimal,” where the protocol was not optimal but did not significantly affect clinical outcomes; and “incorrect,” where the protocol noticeably compromised the examination quality.
Statistical AnalysesR version 4.3.2 (https://www.r-project.org/) was used for statistical analyses. Readers were sub-categorized into radiologists and radiology residents for analysis. The McNemar test was utilized to compare the accuracy between radiologists and radiology residents with vs. without LLM. The Wilcoxon signed-rank test compared the macro sensitivity and the reading time between radiologists with and without LLM and between radiology residents with and without LLM. A p-value of < 0.05 indicated a statistically significant difference.
Comments (0)