
Remember me
In collaborative robotics and intelligent systems, the accuracy of human pose recognition significantly impacts the naturalness and safety of human-machine interactions, establishing it as a core technology for automation systems (Hernández et al., 2021; Liu and Wang, 2021). With the rapid advancement of deep learning and computer vision, pose recognition applications have expanded beyond robot control and monitoring to include augmented reality, sports analysis, and intelligent surveillance (Fan et al., 2022; Desmarais et al., 2021). Additionally, human pose analysis encompasses both external sensing technologies, such as vision-based systems, and internal sensing technologies, such as wearable sensor-based approaches. These two paradigms offer complementary strengths and enable a wide range of applications.
Vision-based pose recognition aims to precisely predict the position and relative relationships of various keypoints by analyzing skeletal information in videos or images (Kim et al., 2023; Liu et al., 2022). However, this task presents numerous challenges, including lighting changes (Lee and Ahn, 2020), partial occlusions (Hernández et al., 2021), diverse poses (Wang et al., 2021), and continuous motion. With the widespread adoption of deep learning, models based on Convolutional Neural Networks (CNN) (Desmarais et al., 2021), Graph Convolutional Networks (GCN) (Li et al., 2021), and Recurrent Neural Networks (RNN) (Zhang et al., 2020) have become mainstream. Methods such as OpenPose (Cao et al., 2017), AlphaPose (Fang et al., 2022), and PoseNet (Kendall et al., 2015) have shown promising results in single and multi-person settings, but they still face limitations in handling complex, dynamic scenes. Moreover, motion continuity and robustness remain challenging due to the inherent nature of visual occlusions, scene clutter, and real-time processing requirements.
Meanwhile, wearable sensor-based approaches, which use biosignals captured from devices such as smart bands, smartphones, or knee bandages, offer a privacy-preserving and unobtrusive alternative for pose analysis. These methods are particularly effective for tasks like gait parameter estimation (Hartmann et al., 2024), high-level human activity recognition (Hartmann et al., 2022), and feature space reduction for efficient classification (Hartmann et al., 2021). For example, Hartmann et al. introduced motion units for generalized sequence modeling of human activities, which address challenges such as motion continuity and robustness (Hartmann et al., 2023). Additionally, frameworks such as ASK have shown how multimodal data fusion can improve activity recognition performance, combining wearable sensor data with contextual information (Hartmann et al., 2020). Furthermore, the development of real-time wearable HAR systems demonstrates the feasibility of meeting strict latency requirements in dynamic environments (Hartmann et al., 2024). Wearable sensors excel in capturing fine-grained motion data, enabling accurate classification of activities such as standing, sitting, walking, jogging, and other locomotion patterns.
While vision-based approaches excel in capturing spatial and contextual information, sensor-based systems are highly robust to occlusions and lighting variations, making them complementary solutions for human pose analysis (Bai et al., 2024). For example, insights from wearable sensor technologies, such as motion continuity modeling and high-level feature extraction, could inspire the development of robust temporal models for vision-based systems. Similarly, multimodal systems that integrate visual and biosignal data hold promise for enhancing robustness, accuracy, and generalization across diverse scenarios. Combining these paradigms offers an opportunity to leverage the strengths of both approaches and address their respective limitations.
Human pose recognition, encompassing both external and internal sensing technologies, has broad applications in modern human-machine interaction, intelligent monitoring, and health management. In collaborative robotics, precise pose recognition enhances robots' understanding and responsiveness to human behavior, enabling them to better adapt to dynamic collaborative environments and achieve more natural interactions. In intelligent surveillance, pose recognition supports anomaly detection, crowd flow analysis, and public safety management. Additionally, in healthcare, pose recognition assists in motion assessment, posture correction, and rehabilitation training, while wearable sensors enable early detection of gait impairments or fall risks in elderly individuals (Hartmann et al., 2024). These technologies also find applications in interactive sports coaching and personalized activity tracking.
Despite significant progress, pose recognition technology still faces challenges in handling occlusions in complex scenes, enhancing motion continuity and robustness, and meeting real-time requirements. For instance, wearable sensing technologies have made strides in addressing motion continuity and real-time processing, yet their reliance on sensor placement limits generalization across datasets. Vision-based approaches, while strong in spatial feature extraction, require innovations in temporal modeling and multimodal data integration to match the robustness of sensor-based systems. Therefore, developing precise, stable, and efficient models that combine external and internal sensing modalities remains a critical research direction. Further innovations in multimodal data fusion, spatial-temporal feature extraction, and cross-domain adaptability will drive advancements in pose recognition and human activity analysis, ultimately enabling more reliable and interpretable systems for real-world applications.
PoseRL-Net is structured with key components to enhance performance: (1) A Spatial-Temporal Graph Convolutional Network (STGCN) module, which extracts spatiotemporal features from the skeletal structure by representing joints as graph nodes and skeletal connections as edges. Through graph convolution, this module learns the temporal relationships between joints, effectively capturing dynamic changes during movements, and improving pose estimation accuracy in complex, real-world scenarios, particularly in environments with occlusion or unpredictable actions. (2) An Attention Mechanism, which dynamically adjusts the weights of each joint, enabling the model to focus on the most critical joints during an action. This mechanism not only enhances recognition robustness in complex, dynamic scenes but also improves model interpretability by highlighting the most important joints in real-time, allowing the model to better handle occlusions and interactions between multiple individuals. (3) A Pose Refinement module with Symmetry Constraints, which refines predictions by enforcing symmetry between left and right joints, ensuring the physical plausibility of the predicted poses. This module reduces errors caused by asymmetric pose predictions and guarantees that the generated poses align with the natural movement patterns of the human body, enhancing both the accuracy and realism of pose estimations.
Contributions of this paper are as follows:
• This paper designs a convolutional network based on spatiotemporal graphs, which effectively extracts spatiotemporal features from the skeletal structure, addressing the challenges of dynamic, collaborative, and occluded environments, thereby enhancing recognition performance in complex real-world scenes.
• The introduction of an attention mechanism allows the model to dynamically focus on the most critical joints, improving the robustness of pose recognition in highly dynamic and interactive scenarios while offering better interpretability by emphasizing key features.
• Through the integration of a posture optimization module with symmetry constraints, the model ensures physically plausible and accurate pose predictions, significantly improving stability and generalization ability in posture recognition tasks, even in challenging environments.
2 Related work 2.1 Robot vision system structureIn collaborative environments, machine vision systems enable robots to perceive their surroundings comprehensively, assisting them in accurately recognizing poses and understanding actions in dynamic and complex scenarios (Turaga et al., 2008), which in turn allows for more precise decision-making and proactive planning (Narneg et al., 2024). Robot vision systems typically integrate various types of sensors, including monocular cameras, stereo cameras, depth cameras, and RGB-D cameras, each with its own advantages and limitations suited to different application contexts.
Monocular cameras are low-cost and easy to set up, making them suitable for basic visual functions in simple environments (Zhang et al., 2021). However, due to limitations in viewing angles and sensitivity to lighting changes, monocular cameras may struggle with robustness and accuracy in complex collaborative scenes. Stereo cameras, on the other hand, provide richer stereo vision information and have higher robustness, though their feature matching and calibration are challenging, computationally intensive, and prone to motion blur.
Depth cameras offer real-time 3D depth information and are highly resilient to lighting and shadow variations, allowing for stable detection under various lighting conditions, albeit with relatively low resolution (Dong et al., 2022; Hao et al., 2024). In comparison, RGB-D cameras (such as Kinect and TOF cameras), which combine color and depth information, achieve high-precision recognition even in complex backgrounds, making them particularly effective in collaborative scenarios with uneven lighting and multiple occlusions (Ning et al., 2024). RGB-D cameras excel in environmental adaptability and real-time performance, effectively discerning occlusion relationships between objects and identifying key features.
In complex collaborative environments, researchers have explored various sensor applications. For instance, Abdelsalam et al. (2024) employed a ZED stereo camera to capture 3D point cloud data in collaborative spaces, constructing unlabelled voxel grids and marking key elements using joint position information, achieving stable pose recognition in complex backgrounds. D'Antonio et al. (2021) utilized a Kinect camera to capture human joint information and employed a bounding circle method to correct joint displacements, enabling accurate recognition in motion. These studies highlight the potential of different vision sensors in collaborative robotic settings, demonstrating how adapting to sensor characteristics enables efficient and accurate human pose recognition in dynamic environments.
2.2 Appearance featuresAppearance features primarily refer to visual attributes such as color, texture, and shape, which play essential roles in image processing. Robot vision systems analyze appearance features in images to recognize key parts of the human body (Kocabas et al., 2021), thereby enabling understanding of poses and capturing actions. However, in complex collaborative environments, recognition based on appearance features is easily affected by lighting changes, shadows, and skin color differences, which can degrade recognition performance.
Color features are a core component of appearance features and are commonly extracted through color histograms or color moments. However, variations in lighting conditions often distort color features, impacting recognition accuracy. To address this, Al Naser et al. (2022) proposed a new algorithm combining the Otsu method and the YCrCb color space, fusing thermal and color information for body part detection. Compared to the traditional OpenPose method, this approach significantly improves recognition speed and reduces the impact of lighting and skin tone variations. Additionally, Zabalza et al. (2019) developed a vision module based on low-cost cameras that uses color detection in the HSV color space, enabling robots to perceive environmental changes more accurately and detect nearby obstacles, thereby enhancing recognition precision under varying lighting and motion conditions.
In practical applications, to maintain high appearance feature recognition performance in environments with significant lighting and shadow changes, researchers typically enhance system robustness through various preprocessing and feature fusion methods. With advancements in machine vision technology, appearance feature processing techniques are continually optimized, enabling robots to capture human poses more efficiently in dynamic environments.
2.3 Local featuresLocal features play a crucial role in robotic vision systems, especially in complex environments with varying lighting conditions or occlusions, where local features are often more robust than appearance features (Bazzani et al., 2013). Local features describe specific details in an image, typically including edges, corners, and texture information, which help robots accurately recognize and locate key parts of the human body.
Common local feature extraction methods include Scale-Invariant Feature Transform (SIFT) (Lowe, 1999), Histogram of Oriented Gradients (HOG) (Dalal and Triggs, 2005), and Oriented FAST and Rotated BRIEF (ORB) (Bansal et al., 2021). SIFT identifies key points in images at different scales and orientations, providing good resistance to occlusion, making it suitable for dynamic scenes. In contrast, ORB combines the FAST feature detection with the BRIEF descriptor, significantly enhancing computational speed and making it ideal for real-time applications. In environments with significant lighting and viewpoint variations, HOG extracts feature information by calculating the gradient direction distribution across different regions of an image, offering high invariance to lighting changes.
In complex collaborative environments, researchers have further improved local feature extraction and matching methods. For instance, Vinay et al. (2015) proposed an interactive face recognition framework based on ORB, incorporating kernel principal component analysis to address nonlinear factors, significantly enhancing recognition accuracy under occlusion conditions. Wu et al. (2017) utilized HOG to extract skeleton feature matrices and proposed a Rotational and Projective Skeleton Signature (RPSS), which demonstrated good real-time performance and robustness, even when spatiotemporal information in action sequences was insufficient.
3 MethodIn this paper, we propose a PoseRL-Net-based robot vision-guided method for recognizing and analyzing human posture and movement in training scenarios, with the experimental architecture shown in Figure 1. By constructing a Spatial-Temporal Graph Convolutional Network (GCN), we treat each human joint as a graph node, with edges representing spatial (skeletal) and temporal (action frame sequence) connections. This method combines the features of Multi-Layer Perceptron (MLP) and the structure of GCN, enabling efficient feature extraction and aggregation of posture data across both spatial and temporal dimensions. The model includes a posture encoding module, spatial-temporal graph convolution layer, motion prediction module, and a posture optimization step, ultimately generating guidance for robot-assisted motion training.
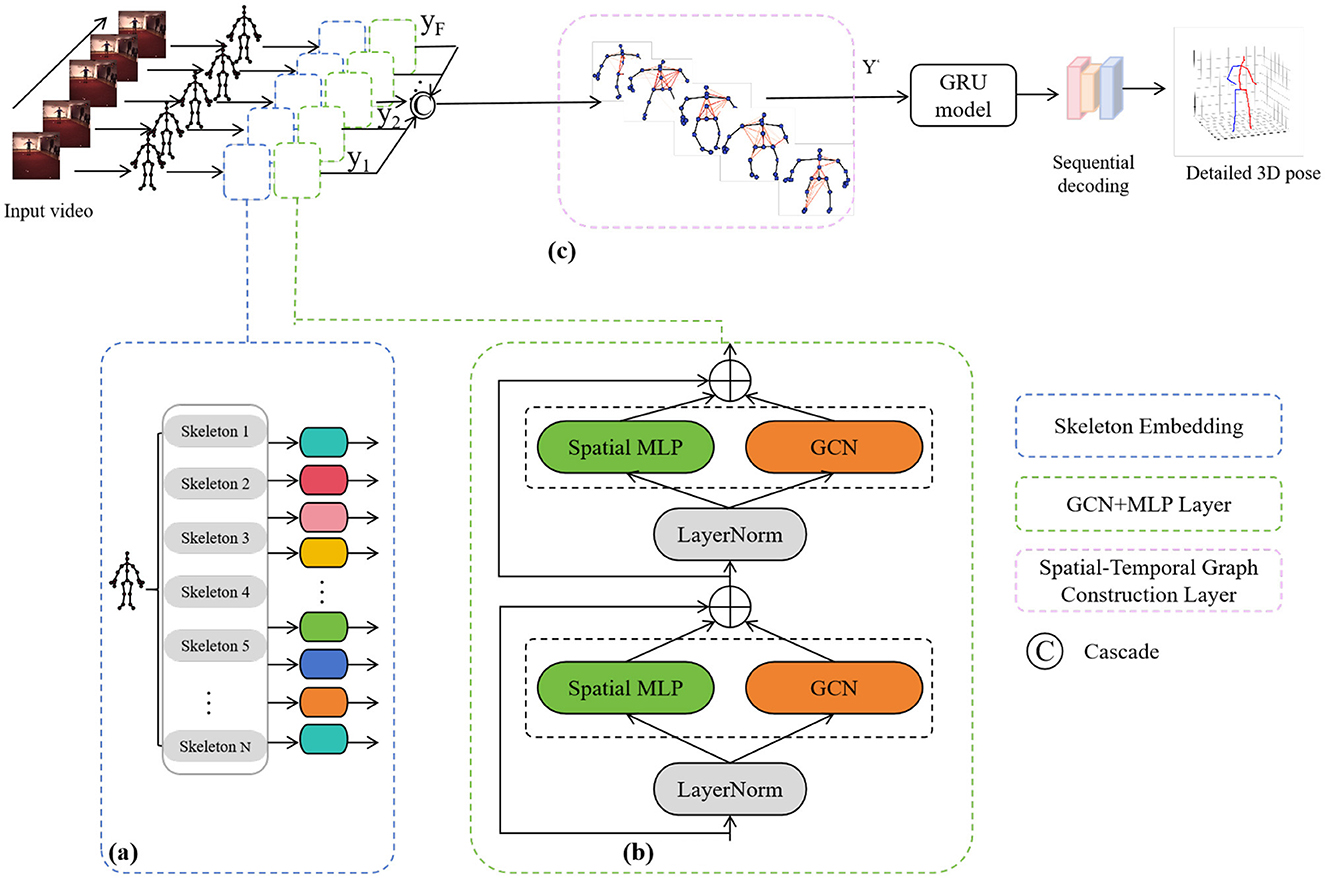
Figure 1. Overview of the proposed PoseRL-Net architecture. (A) Skeleton embedding. (B) GCN+MLP layer. (C) Spatial-temporal graph construction layer.
3.1 Spatial-temporal graph constructionIn the spatial-temporal graph construction, human posture is modeled as a graph structure G = (V, E). Nodes (V) represent the positions of human joints, with each node corresponding to a specific joint. Assuming the human body has M joints, and given an action sequence of T frames, the model contains T×M nodes. The edges (E) are categorized into two types, describing the spatial and temporal relationships between joints. Spatial edges connect related joints within each frame, reflecting the skeletal structure, such as the connection between the knee and hip. Temporal edges connect the same joint across consecutive frames to capture motion trajectories and temporal continuity. This structured graph allows information transfer between nodes, enabling each joint to perceive information from its neighboring joints and capture temporal action changes. The spatial-temporal graph construction can be expressed using the graph Laplacian operator as follows:
where V = represents the set of all nodes, with each vti denoting the i-th joint node at frame t. E = denotes the set of edges, defining the connections between nodes. W = (wij)N×N is the adjacency matrix, where N = T×M represents the total number of nodes in the graph.
The adjacency matrix W is defined as:
wij={1,if (i,j)∈E0,if (i,j)∉E (2)We split the edge set E into spatial and temporal edges. Within each frame t, the skeletal structure is viewed as a static graph, with all adjacent joint nodes connected according to the skeletal relationship. For each joint i, a temporal edge is created between the nodes vti and v(t + 1)i across consecutive frames t and t + 1, representing the joint's positional change over time. To enhance the feature extraction capabilities of the graph convolution, we apply a normalized graph Laplacian matrix:
L=IN-D-12WD-12 (3)where IN is the N×N identity matrix, and D is the degree matrix with diagonal elements Dii=∑jwij, representing the degree of node i. This spatial-temporal graph construction method enables the model to efficiently aggregate spatial and temporal information of joints in the graph convolution layer, providing a more accurate and comprehensive feature representation for 3D posture prediction.
3.2 Graph convolution layerThe Graph Convolution Layer (GCN) is a type of neural network layer designed to process graph-structured data by aggregating information within each node's neighborhood. This allows the central node to integrate information from its adjacent nodes, thereby enhancing the feature representation of each node. In PoseRL-Net, the joint graph structure is constructed through the spatial-temporal graph, after which the feature of each joint is enriched through the GCN layer. This process not only preserves the overall structural information of human joints but also captures temporal action patterns. During graph convolution, each node's features are propagated and merged using the adjacency and degree matrices, capturing complex spatial and temporal relationships. For human pose estimation, this operation enables information propagation between nodes, linking local joint features with the global human skeletal structure, thereby enhancing the model's expressive power and prediction accuracy.
In the GCN module of our PoseRL-Net, Figure 2A shows the joint positions of the human body, while the adjacency matrix in Figure 2B represents the skeletal connections between each pair of joints. The primary operation in the GCN layer is to aggregate and transform each node's features with those of its neighboring nodes. Given a graph G = (V, E):
H(l+1)=σ(D~-12A~D~-12H(l)W(l)) (4)where: H(l): Node feature matrix at the l-th layer, with dimensions N×Cl, where N is the number of nodes, and Cl is the feature dimension at layer l. H(l + 1): Node feature matrix at the l + 1-th layer.A~=A+IN: Adjacency matrix with self-connections, where A is the original adjacency matrix, and IN is the identity matrix, representing each node's self-connection. D~: Degree matrix, where the diagonal elements are defined as D~ii=∑jA~ij.W(l): Learnable weight matrix for the l-th layer, used for linear transformation, mapping features from Cl to Cl + 1.σ: Activation function, using ReLU as the activation function.
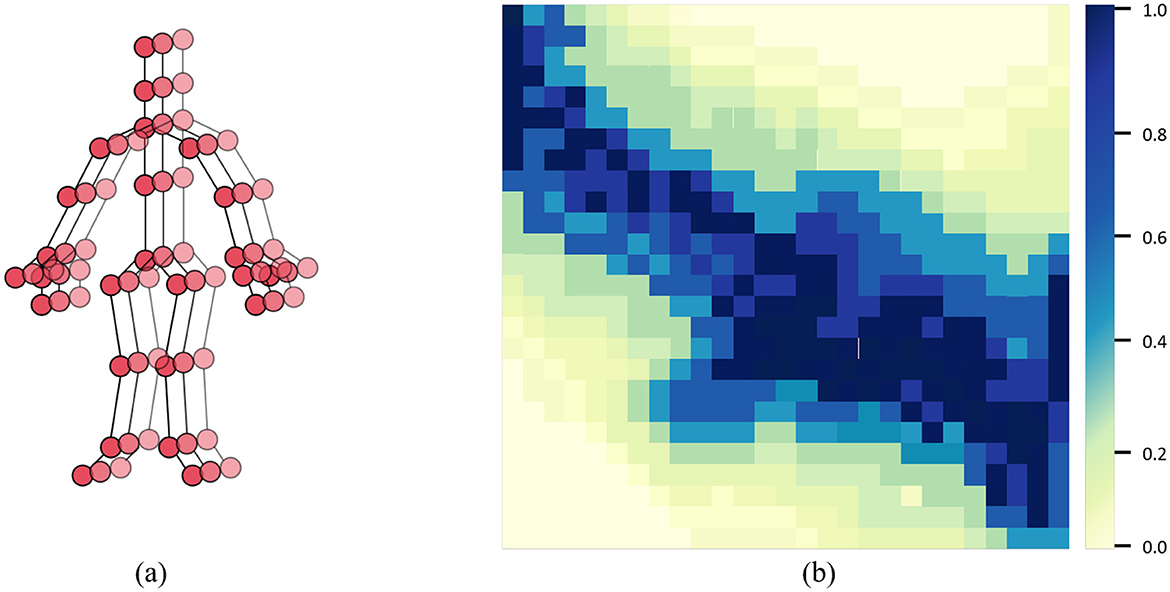
Figure 2. (A) Physical and symmetrical connections in the human skeletal graph. (B) Adjacency matrix used in the GCN module of PoseRL-Net, where different colors represent different types of bone connections.
The GCN layer leverages graph convolution to extract spatial and temporal information between nodes. The spatial-temporal graph construction stage generates an adjacency matrix A~ that contains both spatial and temporal relationships, which the GCN layer then uses to aggregate features within each node's neighborhood. Within the same frame, spatial edges in the GCN layer connect joint nodes to learn the spatial relationships between joints, aiding the model in understanding the spatial structure of the human body. Between adjacent frames, temporal edges connect the same joint's positions across time, capturing the joint's motion trajectory and dynamic characteristics. This design helps the model learn the continuity and evolution of actions. By stacking multiple GCN layers, the model gradually aggregates spatial and temporal features at different scales, enabling a comprehensive understanding of human pose.
3.3 Hierarchical local-global feature extractionThe purpose of local-global feature extraction is to progressively aggregate local joint information into global pose features through a hierarchical approach. This process is achieved via graph pooling and graph upsampling. Specifically, the model begins with fine-grained joint-level features, gradually pooling them to form holistic information about the human body. Then, based on the global information, the model performs upsampling to recover detailed features, leading to more accurate pose predictions.
Initially, starting from the skeleton graph, we use pooling operations to aggregate information from individual joints into more abstract local features, representing different parts of the body. After several layers of pooling, the model obtains a low-resolution global feature map that captures the overall structure of the human body. Based on this global feature, the model progressively upsamples and incorporates lower-level details to generate more precise pose predictions. The features at each layer are integrated during upsampling, enabling collaborative learning of both local and global information.
Through this series of operations, the model can accurately understand the overall structure of the human body while preserving local details, thereby enhancing the accuracy of 3D pose estimation.
In the graph pooling operation at layer l, we aggregate fine-grained features into coarse-grained features. Assuming the input feature is H(l) and the pooled feature is H(l + 1), the pooling process can be defined as:
H(l+1)=P(l)H(l) (5)where H(l) is the node feature matrix at layer l, with dimensions N(l)×C(l), where N(l) is the number of nodes, and C(l) is the feature dimension at layer l. P(l) is the pooling matrix that controls the aggregation of features from layer l to layer l + 1. H(l + 1) is the feature matrix at layer l + 1, with dimensions N(l + 1)×C(l + 1).
During the upsampling process, we progressively restore low-resolution features to higher resolutions to retain local detail information. Assuming the upsampled feature at layer l is H(l):
H(l-1)=U(l)H(l)+H(l-1) (6)where H(l) is the feature matrix at layer l, with dimensions N(l)×C(l). U(l) is the upsampling matrix that maps features from layer l to layer l−1. H(l−1) is the upsampled feature, which is fused with the pre-pooled feature at layer l−1 to restore details.
The hierarchical local-global feature extraction significantly enhances the model's understanding of human poses. The pooling operation allows the model to capture the overall structure of joints at a coarse-grained level, while the upsampling process retains fine-grained details, enabling the model to accurately capture subtle differences in movements during 3D pose prediction. This local-global feature extraction mechanism not only improves the model's expressive capability but also increases its adaptability and robustness to complex human actions.
3.4 Motion prediction and pose refinementThrough motion prediction, the model extends a given sequence of actions over time, capturing pose variations at different time steps. Pose refinement, on the other hand, adjusts pose parameters to ensure that the predicted results conform to natural human movement patterns, thereby enhancing both the accuracy and stability of the model.
The task of motion prediction involves temporally extending the observed sequence of poses to generate future pose information. To achieve this, the model first predicts the next frame's pose based on several past frames. This process utilizes a sequence-based deep learning network, such as a Gated Recurrent Unit (GRU), as illustrated in Figure 3. GRU enables the extension of short-term motion dynamics into long-term predictions. The core idea of motion prediction is to model the trend of joint position changes over time to forecast future joint positions:
Φ^t+1=f(Φt,Φt-1,…,Φt-k;θ)where Φ^t+1 represents the predicted pose at time t + 1, Φt, Φt−1, …, Φt−k are the historical poses from time t−k to t, f is the motion prediction function, and θ denotes the model parameters. This approach allows the model to make long-term predictions of future poses based on historical data.
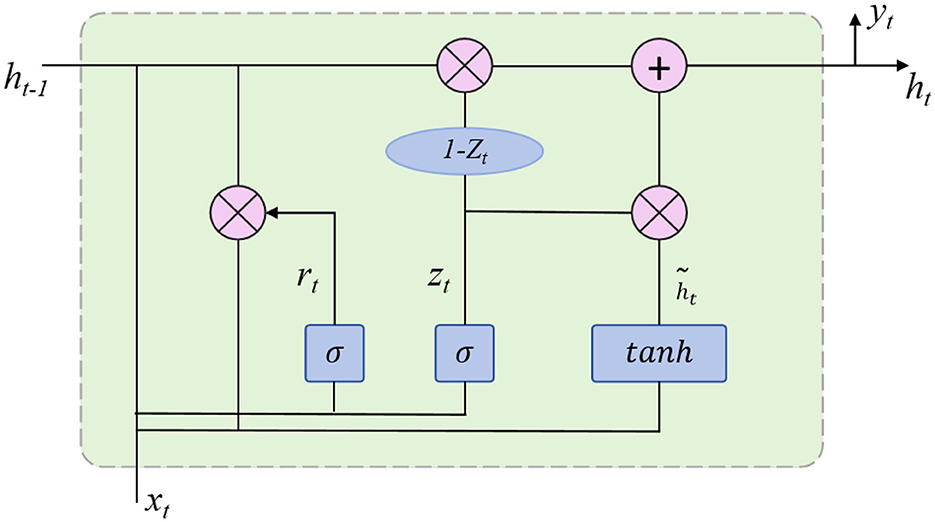
Figure 3. GRU module.
After motion prediction, pose refinement is applied to adjust the predicted 3D poses to align with realistic human motion and symmetry constraints. The goal of pose refinement is to optimize the prediction to ensure that the movements are physically plausible and conform to natural human structures, avoiding abrupt or anatomically inaccurate poses. This optimization typically uses specific loss functions, such as joint symmetry loss and smoothness loss, to constrain the predicted pose. Pose refinement effectively reduces the noise in predictions, thus improving the accuracy of motion forecasting.
Pose refinement primarily involves two aspects: smoothness constraint and symmetry constraint. The smoothness constraint ensures that joint movement remains consistent over time, minimizing sudden jumps, while the symmetry constraint maintains similar length and structure between symmetric joints, preserving human body symmetry.
To quantify these objectives, we design three loss functions: pose loss, smoothness loss, and symmetry loss. Each loss function targets a different aspect of model optimization, working in tandem to improve the quality of pose predictions. The specific formulas are as follows:
Pose loss Lp: This loss function measures the error between the predicted 3D joint coordinates and the ground-truth coordinates, ensuring the accuracy of the predicted pose:
Lp=∑t=1T∑i=1M‖ϕ^t,i−ϕt,i‖2Smoothness loss Ld: This loss function constrains the change in joint positions between consecutive frames, ensuring temporal smoothness of the pose:
Ld=∑t=2T∑i=1M‖ϕ^t,i−ϕ^t−1,i‖2Symmetry loss Ls: This loss function ensures consistent relative positions and structure between symmetric joints (e.g., left and right hands, left and right legs), increasing the physical plausibility of human movement:
Ls=∑t=1T∑b∈ℬ‖ ‖B^t,b‖−‖B^t,C(b)‖ ‖2where T represents the number of time steps, M is the number of joints, and ϕ^t,i and ϕt, i denote the predicted and ground-truth positions of joint i at time t, respectively. In the smoothness loss, ϕ^t,i and ϕ^t-1,i represent the predicted positions of joint i at times t and t−1. In the symmetry loss, B^t,b and B^t,C(b) represent the bone vectors of symmetric joint pairs.
These loss functions work together to improve the model's capability to capture realistic and stable poses, ensuring that PoseRL-Net produces accurate and natural motion predictions across various scenarios.
4 Experiment 4.1 DatasetsThe Human3.6M dataset (Ionescu et al., 2013) is one of the most commonly used 3D human pose datasets, primarily for research in 3D human pose estimation and action recognition. This dataset includes 11 different activity categories, such as walking, running, eating, and talking on the phone. These activities are performed by seven different subjects and captured from multiple camera views (a total of four cameras), providing a rich set of perspectives and fields of view. Human3.6M offers over 3.6 million annotated frames, with each frame containing 3D positions (in millimeters) of 17 joints.
The MPII Human Pose dataset (Mehta et al., 2017) is a standard 2D human pose estimation dataset containing over 25,000 images. Each image is annotated with 16 keypoints (including head, shoulders, elbows, knees, etc.). This dataset covers a wide range of everyday activities, including sports, daily tasks, and complex dance movements. Each image includes 2D joint positions for 16 joints, with poses captured from various scenes and diverse activity types.
4.2 Implementation detailsIn the experimental setup, we systematically trained and evaluated the model to verify the performance of PoseRL-Net. During training, we used the Stochastic Gradient Descent (SGD) optimizer with an initial learning rate of 0.001, a momentum of 0.9, and a batch size of 32. The learning rate was reduced by a factor of 10 every 10 epochs. The training was conducted over 100 epochs, with early stopping applied to monitor the MPJPE metric on the validation set to prevent overfitting. The weights of the loss functions were set as follows: the weight for the pose loss Lp was 1, the weight for the smoothness loss Ld was 1, and the weight for the symmetry loss Ls was 0.01 to balance the contributions of each loss component. The input data was preprocessed with normalization, specifically using OpenCV and Numpy to scale-normalize the 3D joint data from the Human3.6M dataset. Model training and ablation experiments were conducted in the PyTorch framework, with TensorBoard used to log changes in loss and evaluation metrics in real time. The final evaluation metrics included MPJPE, P-MPJPE, MPJVE, parameter count, and Floating Point Operations (FLOPs) to provide a comprehensive analysis of the model's performance and computational complexity.
4.3 Evaluation metricsIn the experimental evaluation, we employed multiple metrics to comprehensively analyze the performance of PoseRL-Net. Specifically, two standard evaluation protocols were used on the Human3.6M dataset (Ionescu et al., 2013). Protocol #1 involves training the model on five subjects (S1, S5, S6, S7, S8) and testing on two unseen subjects (S9, S11) to evaluate the model's generalization to new individuals. This protocol reports the Mean Per Joint Position Error (MPJPE), which measures the average Euclidean distance between predicted and ground-truth 3D joint positions without any alignment. Protocol #2 applies rigid alignment using Procrustes analysis to remove differences in translation, rotation, and scale between the predicted and ground-truth 3D poses, using the same train-test split as Protocol #1. This protocol reports the Pose-processing MPJPE (P-MPJPE), which specifically evaluates the accuracy of pose reconstruction by focusing on the shape similarity of poses rather than their absolute position.
In addition to these metrics, the Mean Per Joint Velocity Error (MPJVE) was utilized in the MPI-INF-3DHP dataset evaluation to assess temporal smoothness by calculating the error in joint velocities between consecutive frames. Lower MPJVE values indicate better continuity and stability in motion sequences. MPJVE was not applied to the Human3.6M dataset, as its evaluation primarily focuses on pose accuracy rather than motion dynamics. Furthermore, computational efficiency was evaluated through the model's parameter count (Parameters, P) and floating-point operations (FLOPs).
4.4 Experimental resultsWe compare PoSER-NET with the most advanced 3D pose estimation models. The results are summarized in Table 1 and visualized in Figure 4 with the drawing of the reference (Li et al., 2023, 2024). This comparison highlights PoseRL-Net's superior predictive accuracy and stability in 3D pose estimation, as demonstrated by key metrics such as MPJPE. Table 1 details the performance of PoseRL-Net across various actions and benchmark models. PoseRL-Net consistently achieved lower MPJPE values across multiple actions, particularly in complex poses such as direction, eating, sitting, and walking. The model achieved an average MPJPE of 35.2, the lowest among all evaluated models, showcasing its exceptional ability to accurately capture human poses across diverse scenarios. The improved performance of PoseRL-Net is attributed to its critical components, including the Spatial-Temporal Graph Convolutional Network (STGC) for efficient spatio-temporal feature extraction, the attention mechanism for focusing on relevant pose features, and the symmetry constraint for maintaining structural consistency in pose predictions. These design choices collectively enabled PoseRL-Net to achieve precise and stable 3D pose estimations, as reflected in the reduced error metrics.
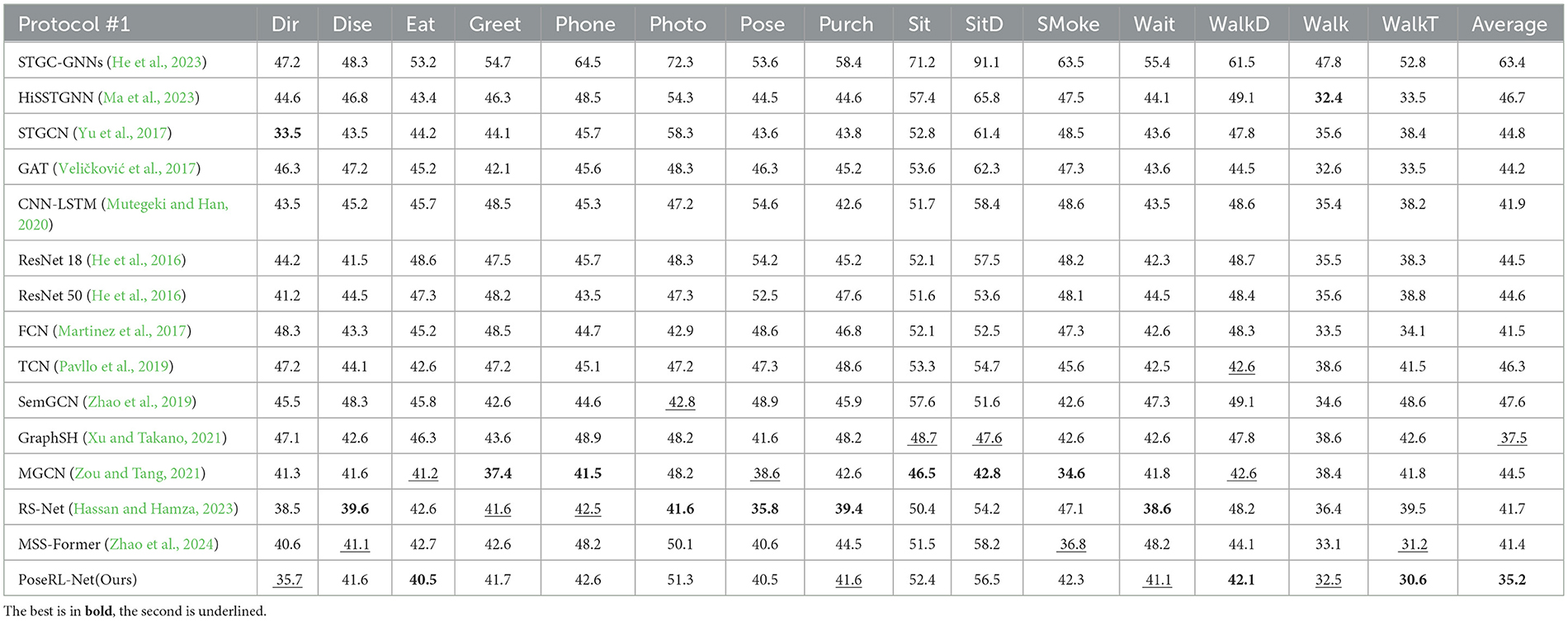
Table 1. Quantitative comparison of Protocol #1 (MPJPE) on the Human3.6M dataset.
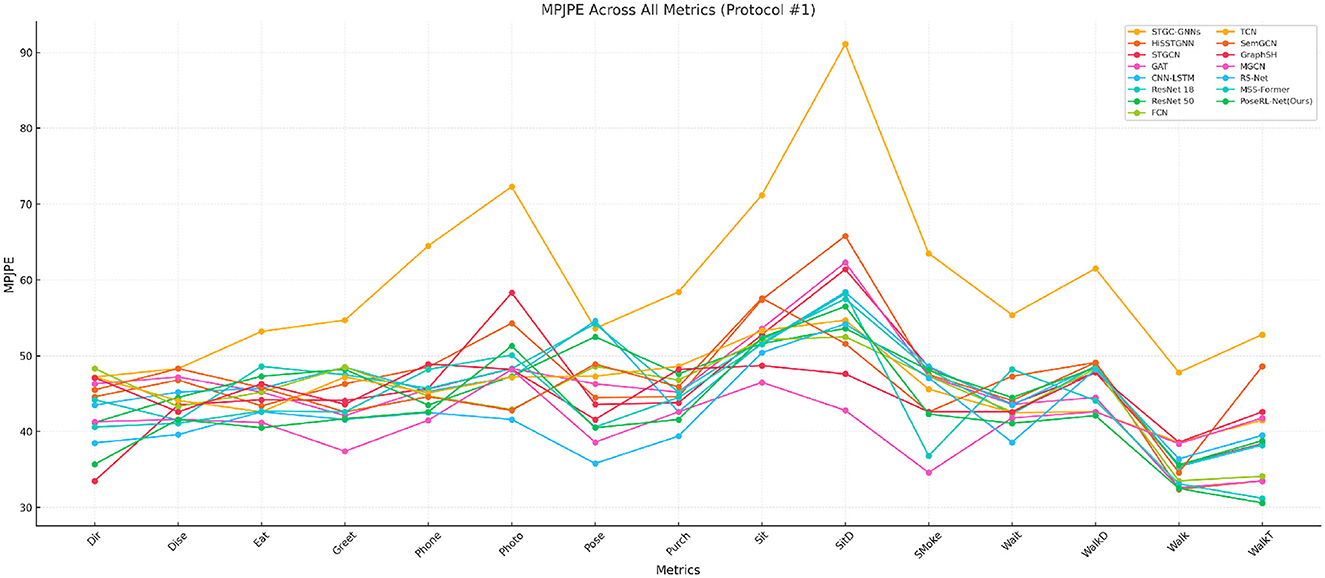
Figure 4. Protocol #1: MPJPE comparison across all models and metrics.
In Table 2 and Figure 5, PoseRL-Net outperformed other models across various actions, achieving the best average P-MPJPE of 34.9, indicating its superior accuracy and reliability in pose estimation tasks. For specific actions such as direction (Dir), eating (Eat), and sitting (Sit), PoseRL-Net demonstrated significant advantages over other models. For instance, it achieved P-MPJPE values of 32.5 for direction and 32.6 for eating, highlighting its ability to generalize across diverse poses and movements.
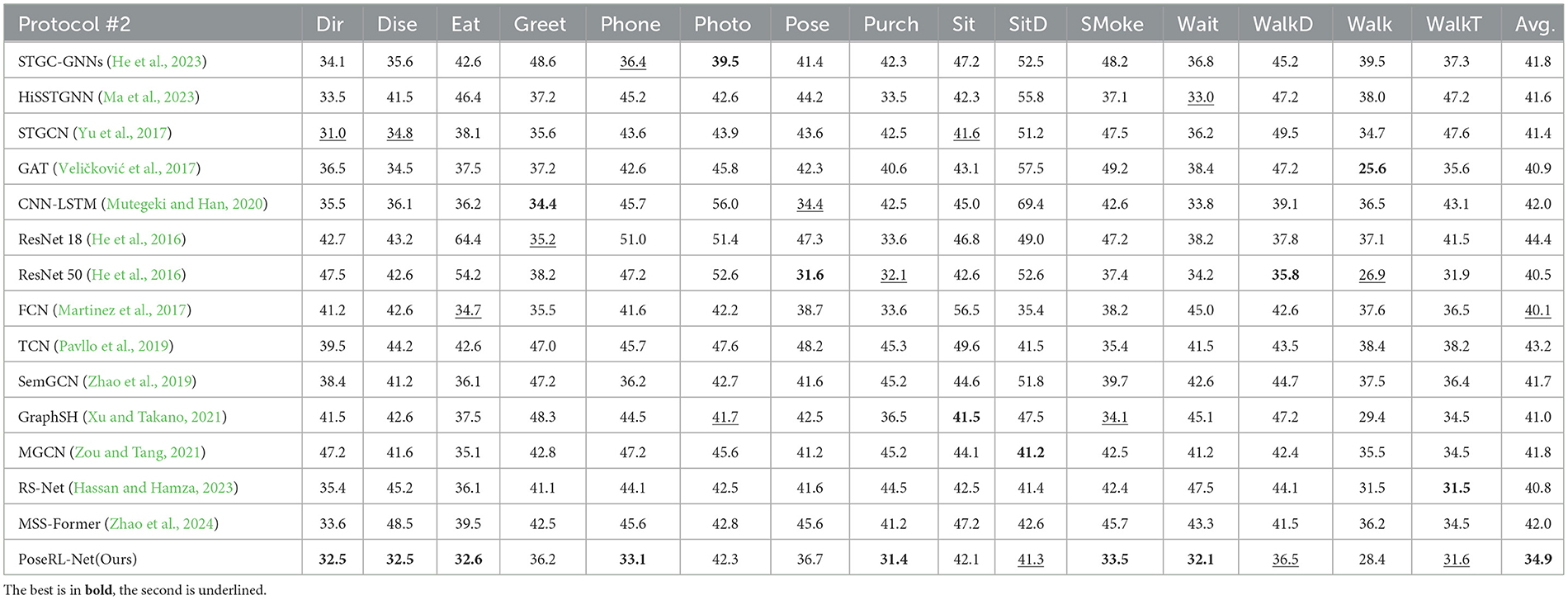
Table 2. Quantitative comparison of Protocol #2 (P-MPJPE) on the Human3.6M dataset.
Comments (0)