
Remember me





ADP is a non-fully-automated normalization tool that enables a user to create standardization rules and apply them to datasets, which is available on GitHub [5]. The ADP normalization scripts are written in Python version 3.10. The core normalization scripts import the libraries os, re, and sys from the Python Standard Library and the non-native library editdistance (imported as ed). ADP is open-source software licensed under GNU GPL-3.0.
ADP’s three core normalization scripts (char_normalizer.py, word_normalizer.py, and phrase_normalizer.py) address the three types of variance outlined in the introduction: character-, word-, and phrase-level variance. At the character and word stages, ADP also logs a Levenshtein distance score for each data item to indicate the extent of the changes made in that stage. ADP uses a script (calculate_metrics.py) to pull relevant metrics from the normalized output files and generate figures using the Python libraries ast, math, matplotlib.pyplot (imported as plt), pandas (imported as pd), seaborn (imported as sns), and warnings.
ADP text normalization workflowAction decision-based normalization of characters and wordsWhile standardizing character variance can be as simple as selecting acceptable special characters and determining case-sensitivity of the data, standardizing word-level variance involves identifying and correcting misspellings in free-text data, a process which is well-known to be “cumbersome” [4]. Normalization tools must also be able to handle “non-standard words,” including numbers, acronyms, and other abbreviations [6]. Some existing word normalization tools overcorrect and have higher rates of “unresolved errors,” or incorrectly-spelled words that the tool swaps with a context-incorrect word; others tend to undercorrect, e.g., by failing to recognize “cant” as a misspelling of “can’t” [4]. ADP uses an iterative character and word normalization process designed to prioritize accuracy of outputs.
The character and word normalization scripts share a similar rule-building workflow. When one of these two scripts is run on a dataset for the first time, it identifies distinct text units (characters or words, which for ADP’s purposes is a sequence of characters delineated by one of several common separators, like hyphens, spaces, or punctuation, or the start or end of a string) and creates a review file to be used for normalization rule-setting.
The review file is a TSV containing one row for each distinct character—except lowercase letters, digits, and a small number of basic punctuation characters, which are treated as valid for character normalization—or word found in the file. It has columns for the character or word, its context (i.e., the data item strings in which that character or word was found), and a count of its occurrences. The review file also has four action columns with the headings “replace_with”, “remove”, “invalidate”, and “allow”. Entering text in one of the action columns (which we refer to as “making an action decision”) sets a rule for the behavior of the script concerning the character or word in that row during future runs of the script. Table 2 describes how entering text in one of the action columns modifies the behavior of the script.
Every time the script is rerun, it moves any review file rows in which an action decision has been made to a reference file, which serves as a bank of rules for the behavior of the script.
Tables 3 and 4 contain examples of the rules applied to these datasets at the character and word stages. These tables are intended to summarize the implementations of the example rules and are abridged from the reference files. The context column, which contains a sample (up to 300 characters in length) of data items containing a given character or word, has been omitted here to improve the readability of this table in the manuscript, and the individual action decision columns are condensed into the singular “Rule” column in the tables below. Please refer to the reference files in the ADP repository to see the full versions of the tables and all rules applied at the character and word stages [5].Footnote 1
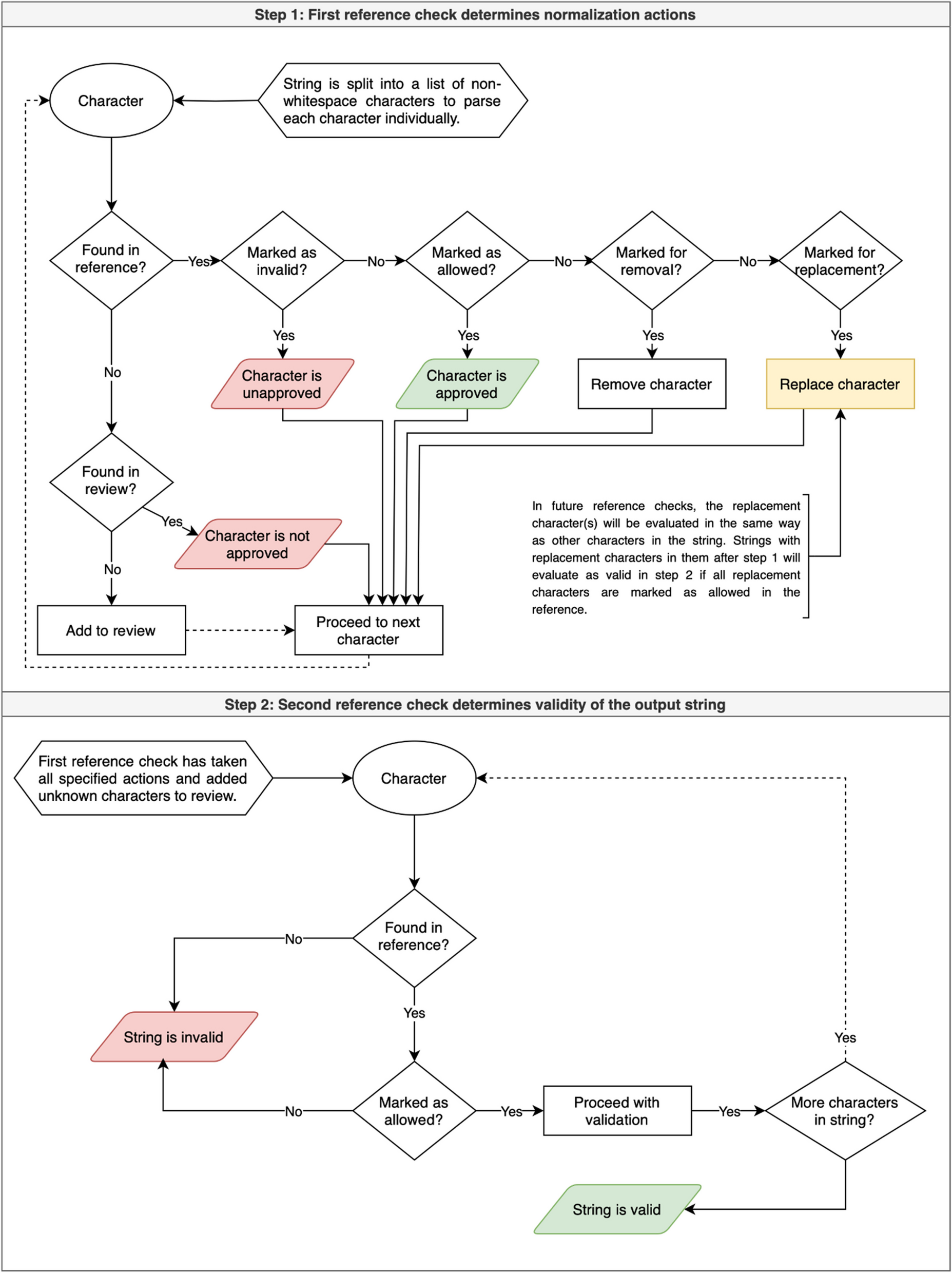
Table 3 Sample character normalization rules & applications to data itemsTable 4 Sample word normalization rules & applications to data itemsFollowing the transfer of rows with new action decisions from the review file to the reference file, the script runs its normalization functions, applying the rules based on the user’s action decisions to the dataset, and it checks for any new text units that do not have a line in either the review file or the reference. See Fig. 1 for a visual representation of how this process works during the character normalization stage.
Fig. 1
Flowchart of ADP character and word normalization processes
In the character normalization stage, data items pass validation if in the second reference check (as shown in the diagram), only allowed characters are found in the string; otherwise, validation fails. Only data items that pass character-level validation are normalized in the word normalization stage. Data items pass word-level validation if in the second reference check, only allowed words are found in the string; otherwise, validation fails.
Pattern-based normalization of phrasesADP phrase normalization uses a process of matching phrase structures to user-defined patterns. This process begins in the word normalization stage. In the word review and reference TSV, there is an additional “category” column. Adding text to this column in the row of a particular word asserts the category to which that word belongs, e.g., in rows for the words “week”, “month”, and “year”, the category has been set to “unit” in the word reference TSV for the age dataset.
When the phrase normalization script is called, it divides the data item into individual words as was done for the word normalization phase. The script tracks the word’s place in the string and any delimiters (including punctuation, whitespace, and the start or end of a string) on either side of the word. Then, it searches the word reference file to see if a category has been assigned to the word; if not, it categorizes the word as “unknown”. The script produces a string that uses a simple grammar to indicate the categories of each word and their position in the string, e.g., the age datum “6 week mean” is parsed as “[number(0)][unit(1)][statistical(2)]”. The phrase categorization string is stored in a dedicated column in the phrase normalization output file to enable the user to determine which phrase structures occur the most frequently in a dataset and develop normalization rules accordingly.
Like the character and word normalization phases, the phrase normalization phase depends on the user to create rules for distinct phrase structures. A dataset’s phrase-type ruleset (found in age_phrase_types.tsv and data_loc_phrase_types.tsv) establishes a name for a pattern, indicates whether or not it is a valid pattern (e.g., in the age dataset, a data item consisting of a number and a unit is valid, but a number by itself is not, as being unitless makes its meaning uncertain), and sets a rule for how phrases that match that pattern should be formatted. See Table 5 for examples.
Table 5 Sample phrase normalization rulesThe categorization string, e.g., [number(0)][unit(1)][statistical(2)] (extracted from “6 week mean”), is matched to a pattern—in this case, the pattern called “statistical”—which matches to the structures of data items that provide a mean or median age value. In the “standard_form” column in the phrase-type ruleset, the user can specify how data items matching a pattern should be formatted. In the case of “6 week mean”, the standard form is represented as “[2]: [0] [1]”, in which the numbers in brackets refer to the indices from the categorization string, and how they should be arranged within the standard form string.
The phrase normalization script generates a blank phrase-type ruleset file if none exists, but if one exists, it checks each data item’s categorization string against any patterns in the file and applies the pattern in the “standard_form” column if applicable by inserting words where their indices are placed in the standard form string. Through this process, “6 week mean” is rearranged to match the standard form string “[2]: [0] [1]”, so the output for that data item is “mean: 6 week”. This workflow ensures that data items with diverse structures, like “6 week mean” and “mean = 6 week”, take on a single standard phrase structure, like “mean: 6 week”. The specific structure we chose for data items of this type is arbitrary; the crucial part is the ability to quickly modify diversely expressed data items into one standard style.
Table 5 contains sample rows from both datasets’ phrase type tables as examples of the rules applied to these datasets. To see the full phrase type tables and all normalization rules applied at the phrase stage, please refer to the relevant files in the ADP repository [5].Footnote 2
Patterns designated as invalid, like the “unitless range” pattern in the age dataset or the “number” pattern from the age dataset, are used to catch and invalidate unusable data: unitless ranges, for instance, are invalidated at the phrase stage because the variety of units used in other age data items renders the meaning a data item like “8–10” ambiguous. Lone numbers in the data-location dataset suffer from the same problem, as “3” could refer to a page number, a line number, a section, etc. For a more thorough explanation of why invalidating these data items is a desirable outcome of the normalization process, please see the Validity Rate by Dataset and Stage section below. If a data item matches to an invalid pattern, it fails validation at the phrase stage and is not normalized. Data items that match to valid patterns, like “range” or “pdb id”, have their component words rearranged to match the format specified in the standard form column to bring them into alignment.
Only data items passing validation at the character and word stages are normalized at the phrase stage. At the phrase stage, data items pass validation only if they match to a pattern designated as valid. The phrase normalization and validation processes are visualized in Fig. 2.
Fig. 2
Flowchart of ADP phrase normalization processes
Measuring string change during normalizationThe ADP normalization code imports the package editdistance to measure the Levenshtein distance between the inputs and outputs in the character and word normalization stages. The normalized output files contain dedicated columns for distance scores comparing the character-normalized string against the original and the word-normalized string against the character-normalized string. Levenshtein distance ceases to be a sensible measure of continuity between input and output at the phrase normalization stage, as desirable and innocuous changes in word order can produce high Levenshtein distance scores. For instance, the hypothetical age data items “18 years average” and “average 18 years” have a Levenshtein distance of 14 despite being semantically identical. While identifying string meaning is not within ADP’s scope, it may prove useful in the future to implement existing Python tools to calculate semantic or cosine similarity as a metric of change at the phrase stage.
Modular normalization & accessory stagesThe ADP normalization process is designed to be modular; because it is split into discrete processes for character, word, and phrase normalization, it is possible to plug in accessory stages to address dataset-specific normalization needs that are not easily handled within the pre-defined stages. The data-location dataset, for instance, implements an accessory stage to split list-like data items into individual strings for data location.
Data-location splittingBecause the data-location dataset contained list-like data items in which several distinct data locations were included in a single data item (e.g., the real data item “Fig. 2A,B,C, Fig. 6.”), phrase normalization would be much more difficult without splitting list-like inputs into multiple items that could then be normalized independently. The script functions as a pre-phrase-normalization stage for the data-location dataset; that script creates multiple rows from list-like data items, transforming the single data item “Fig. 2A,B,C, Fig. 6.” into a set of segments including “Fig. 2a”, “Fig. 2b”, “Fig. 2c”, and “Fig. 6”. Each segment is separated into a distinct row, which is assigned a post-splitting index and an original index to be able to both track segments individually and trace them back to the list-like data items from which they were originally split.
When phrase normalization is applied to the data-location dataset, because the segments have been split into their own rows, they are treated as distinct phrases, allowing all of the “figure x” example segments above to match to a single pattern, rather than needing dedicated patterns to match to each list-like permutation.
Sample normalized data itemsTable 6 contains sample data items from the age and data-location datasets. The columns represent the progression of these data items through the normalization process, with changes made by the character, word, and phrase normalization parts of the code represented in those respective columns. Note that for the data-location dataset, the list-like phrase-normalized strings are split into individual TSV rows for each data item in the list, e.g., the single input data item “Fig. 2A,B,C, Fig. 6.” becomes four output data items: “Fig. 2a”, “Fig. 2b”, “Fig. 2c”, and “Fig. 6”.
Table 6 Sample data items at each stage
Comments (0)