
Remember me




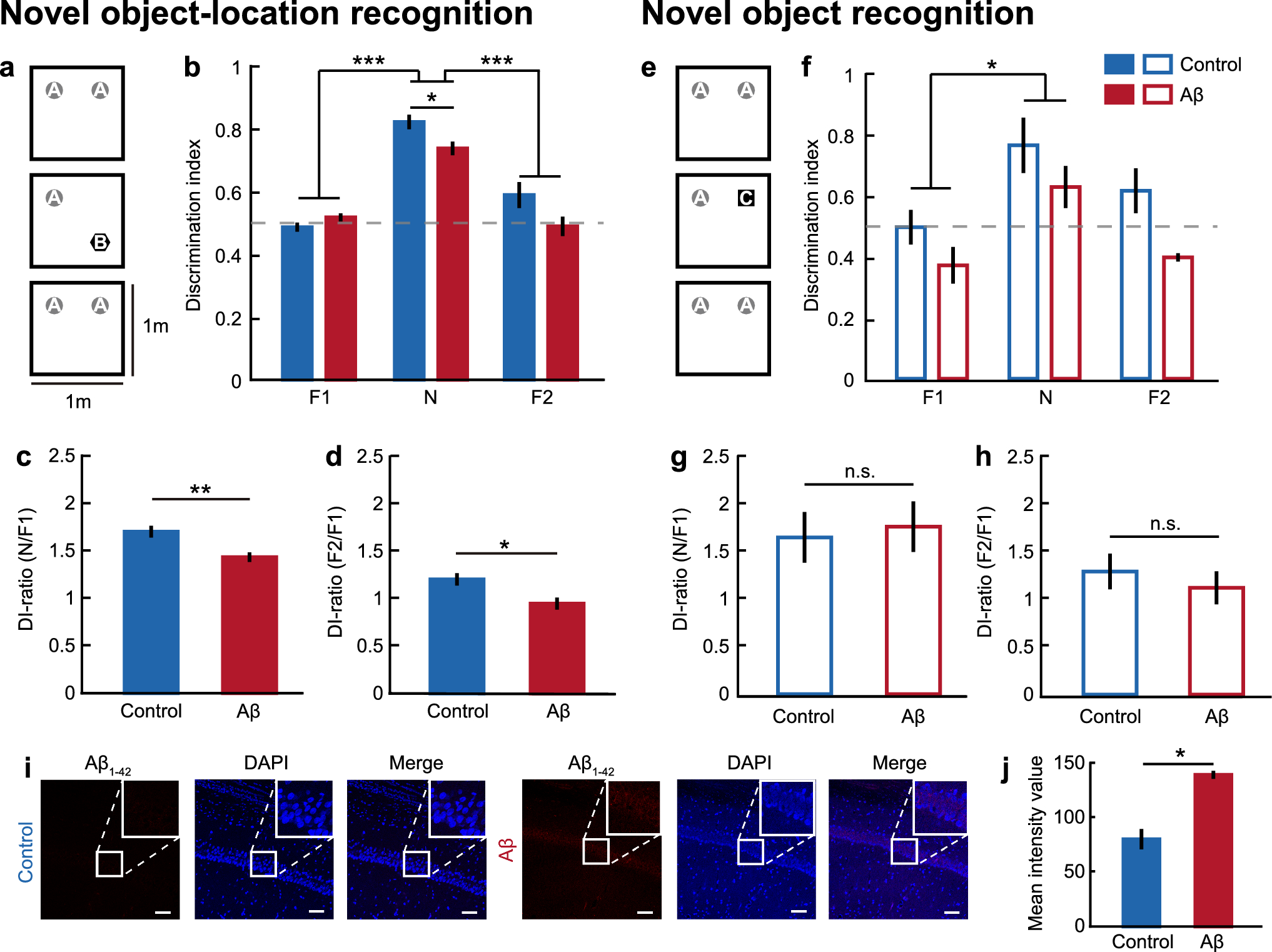
In this work, we introduce BrainNeXt, a novel framework designed to address the challenges associated with brain-related tasks. Furthermore, we propose an innovative FE approach, built upon the foundations of BrainNeXt. In this section, the details of the suggested deep models have been explained.
BrainNeXtIn this research, we introduce BrainNeXt, a novel generation convolutional neural network (CNN) specifically tailored for brain-related tasks. To ensure its efficiency, we leverage the lightweight structure of the ConvNeXtV2 model (Woo et al. 2023). Within the BrainNeXt framework, we employ an inverted bottleneck design for convolutions, employing 7 × 7 and 1 × 1 convolutional kernels. Additionally, maximum pooling with a filter size of 3 × 3 and stride of 2 × 2 is utilized for compression. To augment the number of filters, we leverage depth concatenation. Notably, we have made modifications to the ConvNeXt block, resulting in the creation of our customized ConNeXt block and ConvNeXt V2 block. Figure 2 provides a visual representation of these blocks.
Fig. 2
Block designs of the ConvNeXt, ConvNeXt V2 and the proposed BrainNeXt. **D7 × 7: Depthwise convolution with 7 × 7 sized kernel, LN: Layer Normalization, GELU: Gaussian Error Linear Unit, BN: Batch Normalization, ReLU: Rectified Linear Unit
By using the above block (similar to ConvNeXt blocks), we have created the presented BrainNeXt. The details of the presented BrainNeXt are outlined in Table 3.
Table 3 Details of the BrainNeXt approachTo better explain the proposed BrainNeXt, the graphical explanation is given in Fig. 3.
Fig. 3
Graphical overview of the presented BrainNeXt
As depicted in Fig. 3, the presented BrainNeXt model incorporates several key components. Firstly, we employ a ConvNeXt-like block, which exhibits similarities to the ConvNeXt architecture. Secondly, the DarkNet activation function, utilizing leaky ReLU, is employed to enhance the model's representational capabilities. Finally, the structural elements of the swin transformer or ConvNeXt V2 tiny are incorporated into the model's design.
It is worth noting that the presented BrainNeXt model possesses approximately 8.9 million trainable parameters, rendering it a lightweight convolutional neural network (CNN). This characteristic allows for efficient training and inference while maintaining competitive performance.
BrainNeXt-based exemplar FE approachTo enhance the FE process, we have presented an exemplar (fixed-size patch) model built upon the pre-trained BrainNeXt network. The suggested FE approach, which leverages the capabilities of the presented BrainNeXt, is illustrated in Fig. 4. The diagram provides a high-level overview of the key components and their interactions within the FE approach, showcasing its efficacy in extracting informative features from the data.
Fig. 4
Schematic depiction of the proposed BrainNeXt-based FE architecture. **fp: fixed-size patch, f: feature vector, CI: chronic ischemia
As depicted in Fig. 4, our suggested approach consists of three fundamental phases: (i) exemplar deep feature extraction (FEX), (ii) FS, and (iii) classification.
During the FEX phase, we resize the input image to a size of 224 × 224 and create fixed-size patches with dimensions of 32 × 32. This process results in the creation of 49 patches (\(\right)}^\)). We utilize the global average pooling layer of the proposed BrainNeXt network as the FEX, generating features from both the patches and the raw image. As a result, we obtain a total of 50 feature vectors (49 patches + 1 raw image). Finally, these 50 feature vectors are merged to create a single final feature vector.
The raw image (224 × 224) provides a holistic view of the entire MRI, enabling the model to capture global features, such as general structural patterns and large-scale abnormalities. In contrast, fixed-size patches (32 × 32) focus on localized regions of the image, allowing the model to detect fine-grained details, such as small lesions or subtle abnormalities that may be overlooked in the global context. The global average pooling layer in BrainNeXt extracts representative features from both the patches and the raw image, processing these inputs uniformly to ensure consistency in FEX. Combining features from these two perspectives (global and local) improved the classification ability of the approach. Additionally, using 32 × 32 patches reduces the time complexity of the FEX process while maintaining high performance. Hence, the patch size of 32 × 32 provided the best results.
To select the most informative features from the generated feature vector, we employ NCA (Goldberger et al. 2004). NCA utilizes a distance metric, such as L1-norm/Manhattan distance, to compute the weights of the features. It employs an optimizer, such as stochastic gradient descent (SGD), and generates non-negative features. NCA can be viewed as a FS variant of the k-nearest neighbors (kNN) (Peterson 2009) and is known to enhance the classification capabilities of the classifiers. Given its effectiveness, NCA is a widely recognized and popular FS within the field of FE.
To perform the classification task, we apply SVM (Vapnik 1998) to the selected features obtained from NCA. The following steps outline the methodology employed in this approach.
Step 1: Resize the image to 224 × 224.
Step 2: Apply patch division operator and create 49 patches and the size of each patch is 32 × 32.
$$\begin & fp^ \left( \right) = Im\left( \right),i \in \left\ \right\}, k \in \left\ \right\} \\ & j \in \left\ \right\}, ii \in \left\ \right\},jj \in \left\ \right\}, h \in \left\ \right\} \\ \end$$
(1)
Herein, \(fp\) defines fixed-size patch and \(Im\) is image. The above equation mathematically defines the patch division process.
Step 3: Extract features by using global average pooling layer of the trained BrainNeXt.
$$fv_ = BrainNeXt\left( \right)$$
(2)
$$fv_ = BrainNeXt\left( ,GAP} \right)$$
(3)
where \(fv\) defines the feature vector and the proposed BrainNeXt defines as a function. The parameters of the \(BrainNeXt(.,.)\) function is the used input and the used layer for FEX. In this step, 50 feature vectors have been created. As can be noted in Table 2, the length of each feature vector is 768.
Step 4: Construct final feature vector by merging the generated 50 feature vector.
$$F\left(q+768\times \left(t-1\right)\right)=f_\left(q\right), t\in \left\,\dots ,50\right\}, q\in \left\,\dots ,768\right\}$$
(4)
Herein, \(F\) is the feature vector with a length of 38,400 (= 768 × 50).
Step 5: Identify the most informative 100 features out of the generated 38,400 features.
$$s\left(w,r\right)=F\left(w,index\left(r\right)\right), w\in \left\,\dots ,n\right\},r\in \left\,\dots ,100\right\}$$
(6)
where \(s\) defines the selected feature vector, \(NCA(.,.)\) implies the NCA FS, \(index\) represented the qualified indexes of the features by generating NCA, \(y\) is actual output and \(n\) defines the number of the observation (MRIs).
Step 6: Classify the selected features by deploying SVM.
The given six steps above have been defined the suggested FE approach.
Comments (0)