
Remember me




This study utilized three datasets: (1) public data, (2) a prospectively collected external dataset (participants gave informed consent), and (3) a retrospectively collected in-house dataset (waived informed consent by the local ethics committee, 593/21 S-NP).
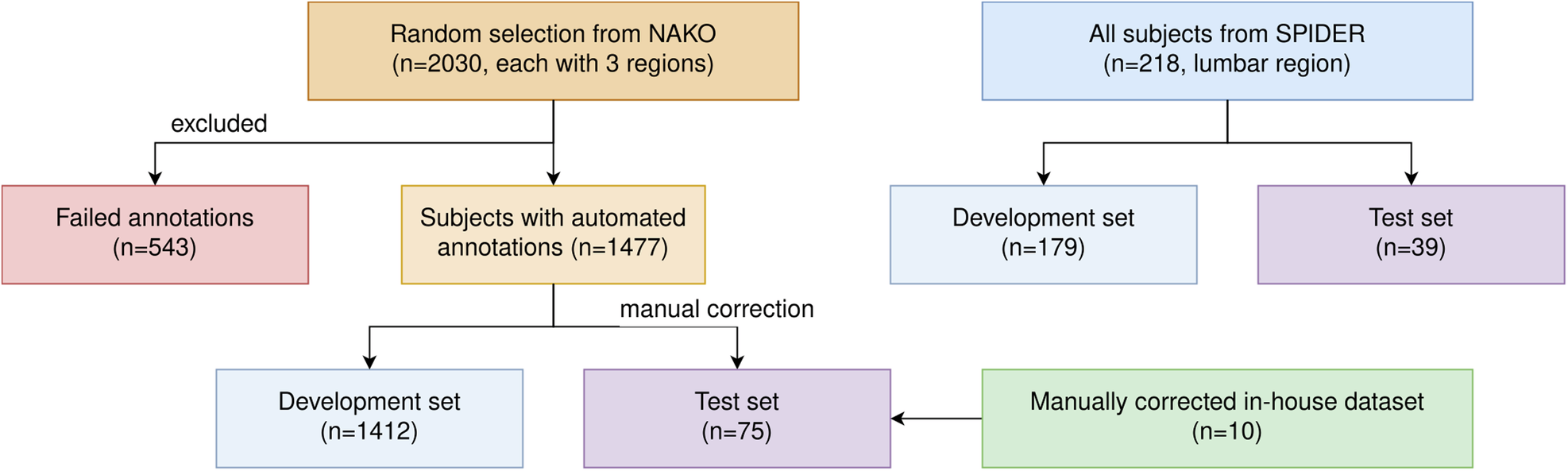
In detail, this study utilized the public SPIDER dataset, [22] a random German National Cohort (NAKO) subset, [23] and an in-house dataset (Table 1). A random test split of 18% (39/218) subjects from SPIDER was used. The ratio of train/test for SPIDER is derived from a previous study [22]. For a second test split, 65 random subjects from the NAKO and the images of the in-house dataset of ten subjects underwent manual correction divided among three experts (J.S., H.S., and B.K.) with 3 years, 3 years, and two years of experience, supervised by an expert (J.S.K.) with 22 years of experience (Fig. 1). The high manual effort and time consumption of this correction process limited the size of this test split. The tool for annotation was ITK-SNAP, [24] a cost-free and simple software for viewing and editing 3D images and segmentations. For training on the NAKO data, no manual annotations were directly utilized. Instead, different automated segmentations were combined as training references.
Table 1 Study cohort demographicsFig. 1
Flow diagram of the investigated study cohort. Flow diagram for subject exclusion from top to bottom for the different datasets (n denotes the number of subjects). Only subjects from the NAKO were excluded for which the automated annotation generation approaches failed
Automated annotationsFrom a previous study by Streckenbach et al [25] manual annotations containing the vertebra corpus, IVD, spinal canal, and sacrum body semantic masks in 180 NAKO subjects were obtained. We trained a default nnUNet model, a widely recognized and powerful tool for image segmentation, using the suggested hyperparameters [26] to replicate this segmentation. This model, alongside the Spinal Cord Toolbox [27] for spinal cord segmentation, was employed to segment the 2030 NAKO subjects. The Spinal Cord Toolbox encountered software issues we could not fix for 543 subjects, which were excluded from further usage, leaving 1477 subjects (1412 of which were used for training).
Adopting Graf et al’s approach, [18] the NAKO training data of T2w sagittal images were translated into artificial CTs. The Bonescreen SpineR tool (Bonescreen GmbH) based on Sekuboyina et al [28] was used to segment the artificial CTs from the second cervical vertebra (C2) to the last lumbar vertebra. These translated annotations yielded nine vertebrae substructures segmentations (corpus, arcus vertebrae, spinous processus, and processus articulares inferiores, superiores, and costales/transversus, the latter three divided into left and right).
The different segmentation masks were merged step by step. Translation-based segmentations were added to the Streckenbach-based ones. When adding, voxels already segmented as a different structure were excluded. Next, the spinal cord voxels were incorporated. Finally, holes between the corpus and IVD regions were filled, and the transition pixels were relabeled as endplates (Fig. 2). As the first cervical vertebra (C1) is not segmented in any of our reference masks, our approach cannot segment this particular vertebra.
Fig. 2
Combination of the automated annotations. Showcase of the three automated annotations and their resulting combined annotation, as a 2D segmentation overlay and a 3D snapshot. a Shows the segmentation made with the training data from Streckenbach et al [25], (b) the SpinalCordToolbox [27] annotation, (c) the annotations derived from translation, and (d) the combination of all three. We observed that the manual segmentation from Streckenbach et al [25] is primarily block-shaped and incomplete, while the translated annotations often segmented too many voxels around the vertebra corpus
This resulted in 14 spinal structures: ten for the vertebral substructures (including endplate), spinal canal, spinal cord, sacrum, and IVD. These automated segmentations served as reference annotations for our training with the NAKO train data.
Segmentation approachOur approach operates in two phases (Fig. 3). Initially, a semantic model segments the scan patch-wise into the 14 semantic labels. For this purpose, a nnUNet 3D architecture [26] is employed.
Fig. 3
Structure of our segmentation approach. The data flow of our proposed method of inference on new T2w sagittal scans. The semantic model segments 14 different spine structures, regardless of field of view. Then, cutouts are made from the segmentation and fed into the instance model. The results are predictions for the individual vertebrae, which are fused together for the vertebra instance mask. Then, using the first segmentation, each voxel in the instance vertebra mask that is not present in the semantic mask is removed. Finally, IVDs and endplates are matched based on a center of mass analysis. The examples shown are predictions of our model on the whole spine
The different instances cannot be trivially computed from this semantic mask, e.g., due to the fusion of vertebrae bodies. Therefore, this study utilizes a sliding window patching approach with a second model (a 3D U-Net [19]) trained to distinguish semantic labels into vertebra instances. This allows us to train the instance segmentation on spatially relative instance labels (i.e., the vertebra instance in the center of the patch) instead of global ones (i.e., the vertebra instance third from the top of the scan). To achieve this, the center of mass position for each vertebra corpus in the semantic mask is computed through connected components analysis. Cutouts of fixed size (248, 304, and 64), with an up-sampled resolution of (0.75, 0.75, and 1.65) and orientation (posterior, inferior, and right), are created around these centers. For each cutout, this second model predicts the three vertebrae around the cutout’s center. During this process, each vertebra appears in multiple cutouts (Fig. 4).
Fig. 4
Example of the instance model. Given the semantic segmentation, cutouts of the exact same size are created. Each of those cutouts (colored boxes) is fed into the instance model. a–c Show the first three predictions of a semantic input. The instance model always predicts the center vertebra of the cutout (green), as well as the one above (red) and below (blue), if visible. Therefore, assuming no erroneous predictions, we get three predictions for all inner vertebrae and two for the outer ones. For example, the second to last vertebra in the figure is predicted thrice, once in each of the three predictions (red, green, blue, from left to right). The combination of all cutout predictions is combined into a vertebra instance mask (d), uniquely labeling each vertebra instance (different colors)
We compute the average Dice score for each vertebra across these appearances. Subsequently, vertebra instances are integrated into the final instance mask from the highest to lowest average Dice score. This approach ensures the least consistent predictions are addressed last, minimizing the potential impact of erroneous predictions on neighboring instances. Notably, this reduces the likelihood of skipping an entire vertebra or merging two vertebrae instances. Significantly, our method relies solely on the semantic mask as input to the instance model. Therefore, the image data is not utilized during this stage. Finally, IVDs and endplate structures from the semantic mask are added to the instance mask and are given instance labels based on the nearest vertebra instance above.
For the training, we used an Nvidia A40 for one GPU day. The detailed configurations and pre-processing used for training each model are shown in Appendix A (Electronic Supplementary Material). One inference run of SPINEPS with both models on a whole-body scan of NAKO with shapes (501, 914, and 16) takes about 50 s to process. This was tested on a separate machine using Ubuntu 22.04 with a GeForce RTX 3090, an AMD Ryzen 9 5900×, and 128 GB RAM. After both semantic and instance segmentation, post-processing techniques are employed.
Post-processingVoxels in the instance mask that are zero in the semantic mask are removed. Furthermore, each connected component present in the semantic mask, but missing in the instance mask, is assigned to the instance with the most neighboring voxels. This ensures consistency in foreground voxels between both masks. A bounding box analysis is used to remove elements isolated from the largest connected component (i.e., the target spine). Additionally, for each articularis inferior and superior connected component, the instances are relabeled based on majority voting. The instance model mostly mixes the neighboring vertebrae instances in those regions by just a few voxels. This ensures consistency and clean edges.
ExperimentsThis study used the nnUNet approach from a previous study as the baseline model [22]. We compared its performance to our SPINEPS approach, training solely on the SPIDER dataset and evaluating the SPIDER test split. As the SPIDER ground truth contains only an instance mask, we compare our instance mask output with it. To enable a semantic evaluation, we derive the anatomic group by its instance, i.e., all vertebra instances receive the same label, before calculating the metrics.
Our approach trained only on the automated annotations of the NAKO training data is evaluated on the manually corrected NAKO test set and in-house data to demonstrate the effectiveness of the automated annotations. Additionally, the performance is compared to a model trained on both NAKO training data and the SPIDER dataset. As only the semantic masks were manually corrected for the test set, only the semantic output of the approach was evaluated. We also omitted evaluations for the sacrum and endplate structure, because they were not part of the manual annotation process of the test data.
Statistical analysisFor evaluation, the Dice similarity coefficient (DSC) and the average symmetric surface distance (ASSD), indicating average distances from segmented edges to reference annotations, is employed. Instance-wise metrics—recognition quality (RQ), segmentation quality (SQ), and panoptic quality (PQ), as described in [29], calculated using panoptica [30]—provided insights into instance prediction performance. Instances with an intersection over a union greater than or equal to 0.5 were considered true positives.
Statistical significance was determined using the Wilcoxon signed-rank test on Dice and RQ metrics, with p < 0.05 indicating statistical significance.
Comments (0)