Discrete trial training (DTT) is a structured teaching method used as a strategy in applied behavior analysis (ABA) therapy to help individuals with autism spectrum disorder (ASD) or other developmental disorders acquire practical skills (Smith, 2001). DTT breaks down the skill into its basic components and teaches each component intensively until the student can learn it enough to move on to the next component. Making this decision is an evidence-based task that typically involves examination of data on the student’s activities across multiple sessions and determining sufficiency based on the proportion of times that the student performed the task correctly out of all opportunities provided for the student to do so. If this proportion meets or exceeds some pre-specified threshold, then the desired mastery level is considered achieved. This threshold is referred to as the performance criterion, also called the mastery criterion, which has been the subject of research interest, especially more recently, with multiple experiments examining how changing the performance criterion impacts maintenance outcomes, which is how well the student retains the skills learned after instruction has ended (Wong et al., 2022a, 2022b). Despite this focus and many significant insights from these studies, a precise framework for DTT practice when it comes to decision-making about performance criterion remains elusive. Various studies have acknowledged the importance of such a framework, and the most recent information suggests there to be considerable variation both in what performance criterion is selected for practice and, more importantly, the rationale used to select the criterion. This paper proposes a flexible model for selecting performance criterion that is grounded on probability theory tailored to the individualized context of DTT.
Development of Performance Criterion in DTT
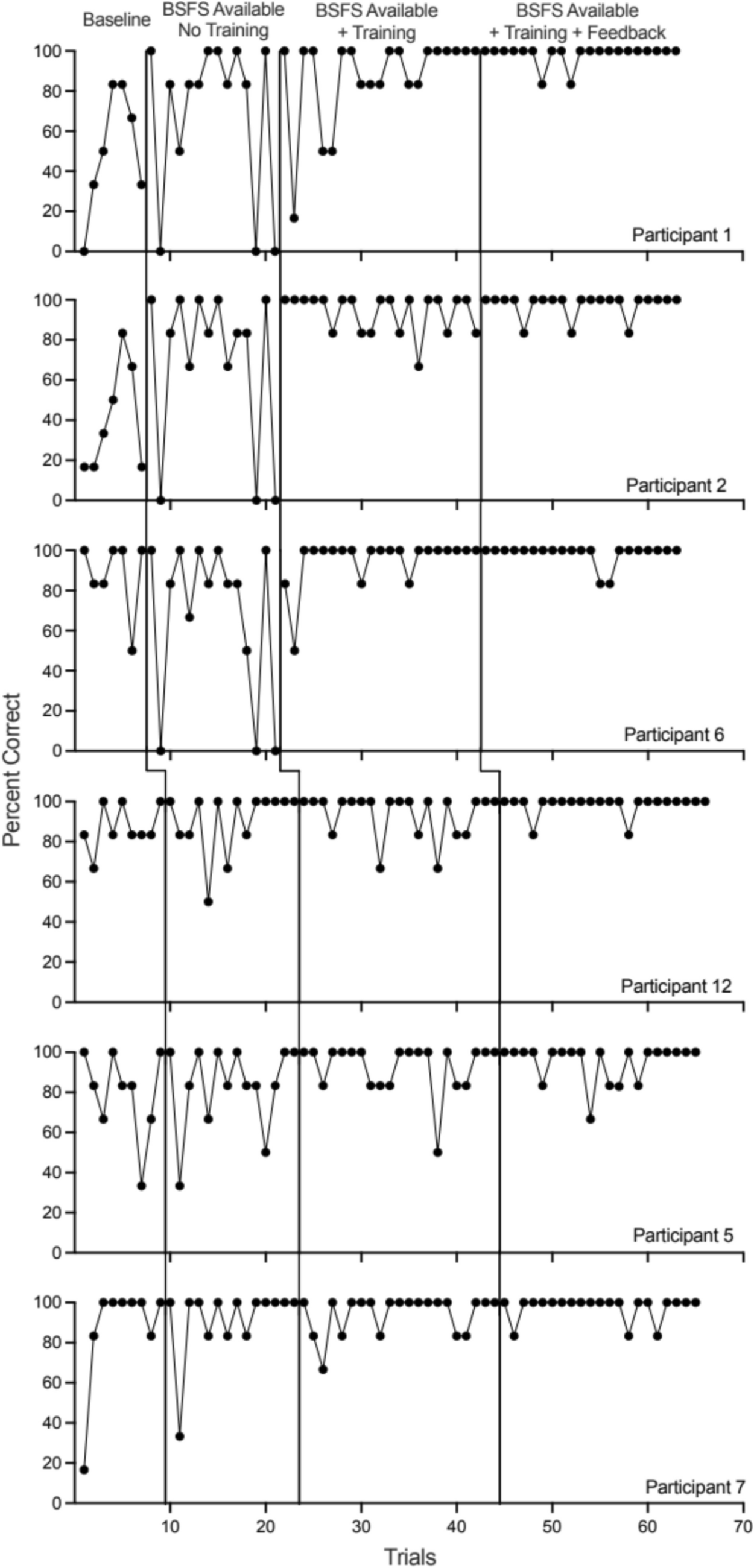
The concept of performance criterion was present from the inception of DTT as a strategy for ABA (Baer et al., 1968; Lovaas, 1977), and at its core is the simple, intuitive idea that in order to infer whether a learner has learned content, one must observe how consistently the learner is able to answer questions on the content correctly. However, exactly how consistent this observation should be has been studied and widely debated for a long time. There is a wealth of literature on small sample experiments that infer how students’ ability to achieve a performance criterion during DTT sessions translates to their ability to demonstrate actual mastery over the content during follow-up/maintenance periods (Longino et al., 2022; Pitts & Hoerger, 2021; Wong et al., 2022a, 2022b). A systematic review conducted on 136 studies across three years found that performance criteria of 80% or higher tended to report corresponding maintenance and generalization outcomes, with studies that used higher criteria tending to report higher follow-up outcomes (Wong et al., 2022a, 2022b). Another study looked into the frequency of reaching the performance criterion and found similar maintenance levels when students needed to pass just one evaluation session at a 90% performance criterion using 15 trials and when they needed to pass three sessions (Schneider et al., 2022). One of the most recent handbooks for ABA practice discussed that different facets of assessment used to determine learning, including choosing the performance criterion, vary considerably across practitioners and researchers (Richling et al., 2023). Surveys conducted on practitioners found that some applied the criterion for trials in a single session, while others applied them to trials across multiple sessions (Richling et al., 2019). Richling et al. (2023) recommended that, at present, most existing literature agrees when it comes to performance criterion selection that it must be high, and they further recommend that it must be heavily nuanced to the skill in question, with some less critical skills being suitable for an 80% criterion while more critical ones that have greater impact when failed require much higher criterion.
Measurement of Individualized, Evidence-Based Learning (MIEBL)
MIEBL provides an explicit framework for selecting performance criterion by applying probability theory. However, this application is nuanced to the context of DTT and, as such, differs from how probability and statistics are typically applied in the field of education. The usual application of probability and statistics in education is perhaps best exemplified by standardized testing, which seeks to identify and replicate optimal teaching methods based on comparing average performance across different schools and among different students (Gershon, 2015). In contrast to this, DTT practice is highly customized to individual students. As such, there is valid skepticism in using measures of average performance across the population of interest as a basis for performance criterion selection for a specific individual. Instead, MIEBL is focused on the individual student and offers a protocol for selecting performance criterion based only on factors concerning the individual. As will be explained, this does run into some difficulty in applying probabilistic concepts, particularly in terms of dealing with very small sample sizes, but MIEBL is designed to operate within those limitations.
We begin by defining \(\Omega\) as a DTT skill component space. Its elements are items from a specific skill component that is desired for a student to learn. For example, \(_\) can be the DTT skill component space for recognizing and uttering the sight word “house” under some defined conditions (e.g., level of distraction, presence of prompting, motivating operations). The elements of \(_\) can be any trial used by the practitioner in determining whether the student can accomplish this component. Thus, the process of preparing a session where the student will be assessed in their ability to utter “house” in 5 trials can be framed as selecting 5 items “at random” from \(_\). “At random” is placed in quotes because the trials are not actually selected at random in the probabilistic sense, but purposefully according to some thoughtful variation of the task. The point is that these items are ideally exchangeable, so that any item selected from this space would function practically the same in testing the student’s mastery level of \(_\).
Next, we define student space \(S\) as the totality of all knowledge and skills possessed by the student on all topics at a given point in time. Simply put, it is everything that the student knows about everything. Thus, the elements of \(S\) are some uncountably many ordered pairs \((_,_ )\), where \(_\) is the DTT skill component space and \(_\) is the mastery level of the student over that space. Technically, \(_\) is the probability that student \(S\) can accomplish an item selected from \(_\). It is important to differentiate \(_\) from the performance criterion; \(_\) represents the actual mastery level of the student, which is an intangible and exactly unknowable property. For example, for \(_\), \(_\) represents the likelihood that the student will be able to utter the word “house” in the correct context under conditions defined by \(_.\) Thus, a student \(S\) who has\((_,_=1 )\), is someone who has completely mastered the task of uttering “house” and can do this correctly every time. In contrast, the performance criterion is some tangible, known number that is preset by the practitioner which we define as \(\tau\). For example, a practitioner can set a performance criterion of \(\tau =80\%\) in 10 trials. Which means that they will consider that the student has mastered the task if the student gets 8 out of 10 trials correctly. If we define the number of trials as \(n\) and the number of correct responses as \(x\), then the practitioner is making the inference that if \(x/n\ge \tau\), then \(p\ge ^\), where \(^\) is some desired value for actual mastery. Suppose we set \(^=70\%\), then \(\tau =80\%\) would mean that the practitioner believes that if the student is able to correctly utter “house” 80% of the time during assessment, then even if they keep providing the student with more trials, the student will be able to respond correctly to those as well at least 70% of the time. That is, an observed mastery of \(\tau\) implies an actual mastery of at least \(^\).
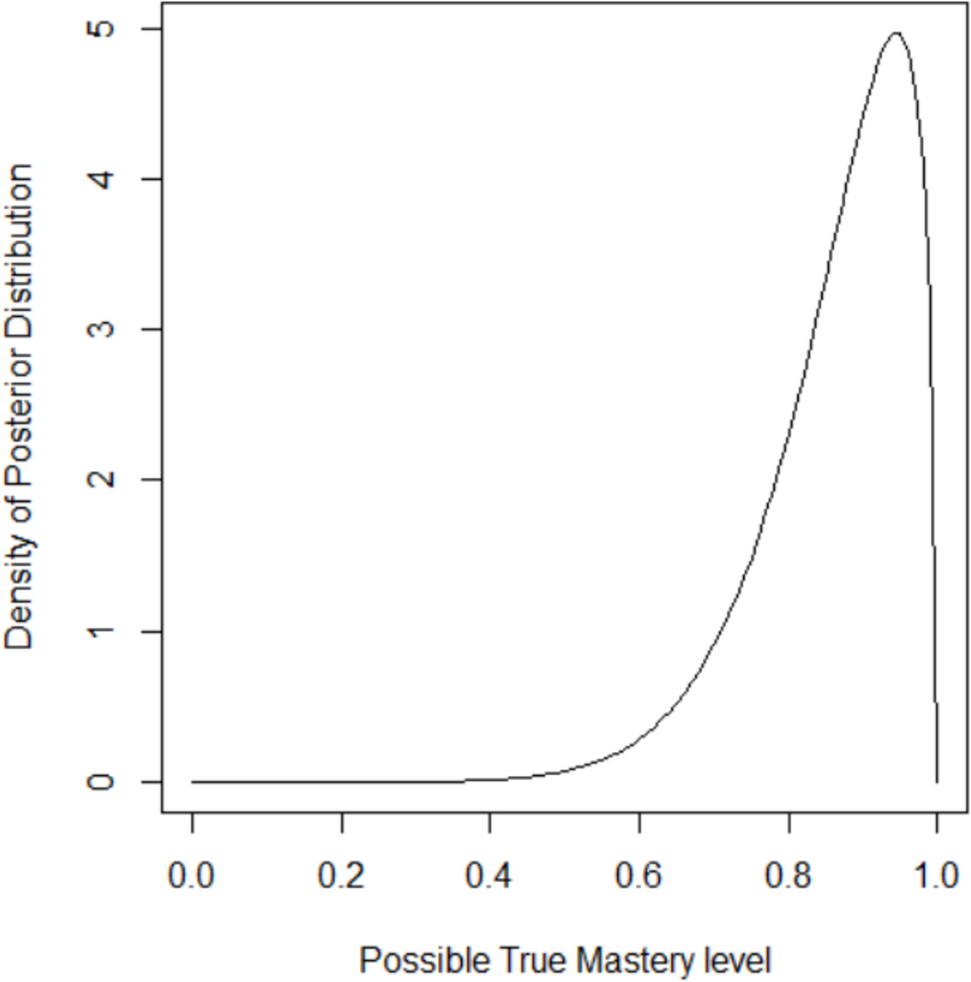
Therefore, the core of MIEBL’s purpose is enabling the practitioner to select a proper \(\tau\) to have confidence that a student reaching this criterion has a true mastery \(p\) that is at least as good as some desired \(^\). In the language of probability, this seeks to answer the question of \(\text(p\ge ^| x/n\ge \tau )=b\); what is the probability that the true mastery is at least the desired mastery level given that the data shows the student meeting the performance criterion? This is what is known as a Bayesian inference question (Held & Sabanés Bové, 2020). A technical discussion on how to compute these probabilities is provided in the supplementary materials.
In Table 1, these quantities are computed for a desired mastery level \(^=90\%\) using different numbers of trials \(n\). This table demonstrates how each performance criterion choice reflects confidence regarding the inference that the student’s true mastery level is 90%. The results demonstrate that when \(n=5\), a performance criterion of 80% is not meaningful, as even if the student reaches this, the Bayesian inference states that the probability their actual mastery is at least 90% is only 0.20. Pragmatically, if a practitioner is aiming at such a high level of actual mastery at \(n=5\), a criterion of 100% makes more sense. This allows the practitioner to infer that if a student reaches this criterion, the Bayesian probability that their actual mastery \(p\geq90\%\) is 0.71.
Table 1 Bayesian probabilities indicating mastery of a skill component space for p* = 90%As such, MIEBL is very dynamic in terms of the choices that practitioners make. It does not seek to dictate what criterion should be used but provides a quantified description of the consequences of selecting each criterion in practice. Table 1 shows that for attempting to determine if a student reaches a true mastery level of 90%, a larger number of trials is needed. Suppose that the practitioner is willing to accept a true mastery standard of 70%, then the probabilities are recomputed with results shown in Table 2. Lowering the desired mastery level from 90% to 70% predictably makes every performance criterion better at supporting the decision that this new true mastery level is achieved. Thus, a practitioner who is willing to probe for a true desired mastery level of at least 70% instead of 90% can choose a performance criterion of 90% for \(n=10\) and be confident that the Bayesian probability that a student meets a true mastery level of at least 70% given than they get at least 9 out of 10 trials correctly is 0.93. If this is not sufficient confidence, then the practitioner can opt for a performance criterion of 100% and have a Bayesian probability of 0.99.
Table 2 Bayesian probabilities indicating mastery of a skill component space for p* = 70%



Comments (0)