Bommasani R, Hudson DA, Adeli E, Altman R, Arora S, von Arx S, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258. 2021. arXiv:2108.07258.
Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, et al. Learning transferable visual models from natural language supervision. Int Conf Mach Learn. 2021;139:8748–63.
Google Scholar
Caron M, Touvron H, Misra I, Jégou H, Mairal J, Bojanowski P, et al. Emerging properties in self-supervised vision transformers. Proceedings of the IEEE/CVF international conference on computer vision; 2021; 9650–60.
Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, Neelakantan A, et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165. 2020;1. arXiv:2005.14165.
Brown T, Mann B, Ryder N, Subbiah M, Kaplan JD, Dhariwal P, et al. Language models are few-shot learners. Adv Neural Inf Process Syst. 2020;33:1877–901.
Google Scholar
Chowdhery A, Narang S, Devlin J, Bosma M, Mishra G, Roberts A, et al. Palm: scaling language modeling with pathways. J Mach Learn Res. 2023;24(240):1–113.
Google Scholar
Taylor R, Kardas M, Cucurull G, Scialom T, Hartshorn A, Saravia E, et al. Galactica: A large language model for science. arXiv preprint arXiv:2211.09085. 2022. arXiv:2211.09085.
Touvron H, Lavril T, Izacard G, Martinet X, Lachaux M-A, Lacroix T, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971. 2023. arXiv:2302.13971.
Yang X, Chen A, PourNejatian N, Shin HC, Smith KE, Parisien C, et al. Gatortron: A large clinical language model to unlock patient information from unstructured electronic health records. arXiv preprint arXiv:2203.03540. 2022. arXiv:2203.03540.
Boecking B, Usuyama N, Bannur S, Castro DC, Schwaighofer A, Hyland S, et al., editors. Making the most of text semantics to improve biomedical vision–language processing. European conference on computer vision; 2022: Springer.
Li Y, Li Z, Zhang K, Dan R, Jiang S, Zhang Y. ChatDoctor: a medical chat model fine-tuned on a large language model meta-AI (LLaMA) using medical domain knowledge. Cureus. 2023;15(6):e40895. https://doi.org/10.7759/cureus.40895.
Article
Google Scholar
Wang J, Zhu H, Wang SH, Zhang YD. A review of deep learning on medical image analysis. Mobile Netw Appl. 2021;26(1):351–80. https://doi.org/10.1007/s11036-020-01672-7.
Article
Google Scholar
Suganyadevi S, Seethalakshmi V, Balasamy K. A review on deep learning in medical image analysis. Int J Multimed Inf Retr. 2022;11(1):19–38. https://doi.org/10.1007/s13735-021-00218-1.
Article
Google Scholar
Azad B, Azad R, Eskandari S, Bozorgpour A, Kazerouni A, Rekik I, et al. Foundational models in medical imaging: a comprehensive survey and future vision. arXiv. arXiv preprint arXiv:2310.18689. 2023;10. arXiv:2310.18689.
Hartsock I, Rasool G. Vision-language models for medical report generation and visual question answering: a review. Front Artif Intell. 2024;7:1430984. https://doi.org/10.3389/frai.2024.1430984.
Article
Google Scholar
Zhang S, Metaxas D. On the challenges and perspectives of foundation models for medical image analysis. Med Image Anal. 2024;91:102996. https://doi.org/10.1016/j.media.2023.102996.
Article
Google Scholar
Rajpurkar P. CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning. ArXiv abs/1711. 2017.5225. arXiv:1711.05225.
Ronneberger O, Fischer P, Brox T. U-net: convolutional networks for biomedical image segmentation. Medical image computing and computer-assisted intervention–MICCAI 2015. 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer; 2015. pp. 234-41. https://doi.org/10.1007/978-3-319-24574-4_28.
Sobek J, Medina Inojosa JR, Medina Inojosa BJ, Rassoulinejad-Mousavi S, Conte GM, Lopez-Jimenez F, et al. MedYOLO: a medical image object detection framework. J Imaging Inform Med. 2024;37(6):3208–16. https://doi.org/10.1007/s10278-024-01138-2.
Article
Google Scholar
Lehmann TM, Güld MO, Thies C, Fischer B, Spitzer K, Keysers D, et al. Content-based image retrieval in medical applications. Methods Inf Med. 2004;43(4):354–61.
Article
Google Scholar
Ben Abacha A, Hasan SA, Datla VV, Demner-Fushman D, Müller H. Vqa-med: Overview of the medical visual question answering task at imageclef 2019. Proceedings of CLEF (Conference and Labs of the Evaluation Forum) 2019 Working Notes; 2019:9–12.
Wang X, Peng Y, Lu L, Lu Z, Summers RM. Tienet: text-image embedding network for common thorax disease classification and reporting in chest x-rays. Proceedings of the IEEE conference on computer vision and pattern recognition. 2018:9049–58.
Hou L, Agarwal A, Samaras D, Kurc TM, Gupta RR, Saltz JH. Robust histopathology image analysis: To label or to synthesize?. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition; 2019;2019:8533-42. https://doi.org/10.1109/CVPR.2019.00873.
Jing B, Xie P, Xing E. On the automatic generation of medical imaging reports. arXiv preprint arXiv:1711.08195. 2017. 10.48550/arXiv:1711.08195.
Jia C, Yang Y, Xia Y, Chen Y-T, Parekh Z, Pham H, et al. Scaling up visual and vision-language representation learning with noisy text supervision. In: International conference on machine learning, PMLR. 2021.
Fürst A, Rumetshofer E, Lehner J, Tran VT, Tang F, Ramsauer H, et al. Cloob: Modern hopfield networks with infoloob outperform clip. Adv Neural Inf Process Syst. 2022;35:20450–68.
Google Scholar
Li Y, Liang F, Zhao L, Cui Y, Ouyang W, Shao J, et al. Supervision exists everywhere: a data efficient contrastive language-image pre-training paradigm. arXiv preprint arXiv:2110.05208. 2021. arXiv:2110.05208.
Wang Z, Yu J, Yu AW, Dai Z, Tsvetkov Y, Cao Y. Simvlm: simple visual language model pretraining with weak supervision. arXiv preprint arXiv:2108.10904. 2021. 10.48550/arXiv:2108.10904.
Li LH, Yatskar M, Yin D, Hsieh C-J, Chang K-W. Visualbert: a simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557. 2019. 10.48550/arXiv:1908.03557.
Chen J, Guo H, Yi K, Li B, Elhoseiny M. Visualgpt: Data-efficient adaptation of pretrained language models for image captioning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
Alayrac J-B, Donahue J, Luc P, Miech A, Barr I, Hasson Y, et al. Flamingo: a visual language model for few-shot learning. Adv Neural Inf Process Syst. 2022;35:23716–36.
Google Scholar
Phan VMH, Xie Y, Qi Y, Liu L, Liu L, Zhang B, et al. Decomposing disease descriptions for enhanced pathology detection: a multi-aspect vision-language pre-training framework. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
Luo H, Zhou Z, Royer C, Sekuboyina A, Menze B. DeViDe: Faceted medical knowledge for improved medical vision-language pre-training. arXiv preprint arXiv:2404.03618. 2024. https:/doi.org/10.48550/arXiv:2404.03618.
Liu C, Cheng S, Shi M, Shah A, Bai W, Arcucci R. IMITATE: clinical prior guided hierarchical vision-language pre-training. IEEE Trans Med Imaging. 2024. https://doi.org/10.1109/TMI.2024.3449690.
Article
Google Scholar
Wang P, Zhang H, Yuan Y. MCPL: multi-modal collaborative prompt learning for medical vision-language model. IEEE Trans Med Imaging. 2024. https://doi.org/10.1109/TMI.2024.3418408.
Article
Google Scholar
Moon JH, Lee H, Shin W, Kim Y-H, Choi E. Multi-modal understanding and generation for medical images and text via vision-language pre-training. IEEE J Biomed Health Inform. 2022;26(12):6070–80. https://doi.org/10.1109/JBHI.2022.3207502.
Article
Google Scholar
Wang R, Yao Q, Lai H, He Z, Tao X, Jiang Z, et al. ECAMP: entity-centered context-aware medical vision language pre-training. arXiv preprint arXiv:2312.13316. 2023. 10.48550/arXiv:2312.13316.
Yan B, Pei M. Clinical-bert: vision-language pre-training for radiograph diagnosis and reports generation. Proc AAAI Conf Artif Intell. 2022. https://doi.org/10.1609/aaai.v36i3.20204.
Article
Google Scholar
Chambon P, Bluethgen C, Delbrouck J-B, Van der Sluijs R, Połacin M, Chaves JMZ, et al. Roentgen: vision-language foundation model for chest x-ray generation. arXiv preprint arXiv:2211.12737. 2022. 10.48550/arXiv:2211.12737.
Huemann Z, Tie X, Hu J, Bradshaw TJ. ConTEXTual net: a multimodal vision-language model for segmentation of pneumothorax. J Imaging Inf Med. 2024. https://doi.org/10.1007/s10278-024-01051-8.
Article
Google Scholar
Li Q, Yan X, Xu J, Yuan R, Zhang Y, Feng R, et al. Anatomical structure-guided medical vision-language pre-training. In: International Conference on Medical Image Computing and Computer-Assisted Intervention; 2024: Springer. https://doi.org/10.1007/978-3-031-72120-5_8.
Liu C, Cheng S, Chen C, Qiao M, Zhang W, Shah A, et al. M-flag: medical vision-language pre-training with frozen language models and latent space geometry optimization. In: International conference on medical image computing and computer-assisted intervention; 2023: Springer. https://doi.org/10.1007/978-3-031-43907-0_61.
Thawakar OC, Shaker AM, Mullappilly SS, Cholakkal H, Anwer RM, Khan S, et al., editors. XrayGPT: Chest radiographs summarization using large medical vision-language models. In: Proceedings of the 23rd workshop on biomedical natural language processing. 2024. https://doi.org/10.18653/v1/2024.bionlp-1.35.
Zhang X, Meng Z, Lever J, Ho ES. Libra: Leveraging temporal images for biomedical radiology analysis. arXiv preprint arXiv:2411.19378. 2024. arXiv:2411.19378.
Chen H, Zhao W, Li Y, Zhong T, Wang Y, Shang Y, et al. 3d-ct-gpt: generating 3d radiology reports through integration of large vision-language models. arXiv preprint arXiv:2409.19330. 2024. arXiv:2409.19330.
Hamamci IE, Er S, Almas F, Simsek AG, Esirgun SN, Dogan I, et al. Developing generalist foundation models from a multimodal dataset for 3D computed tomography. 2024; https://doi.org/10.21203/rs.3.rs-5271327/v1.
Lai H, Jiang Z, Yao Q, Wang R, He Z, Tao X, et al. E3D-GPT: enhanced 3D visual foundation for medical vision-language model. arXiv preprint arXiv:2410.14200. 2024. arXiv:2410.14200.
Blankemeier L, Cohen JP, Kumar A, Van Veen D, Gardezi SJS, Paschali M, et al. Merlin: a vision language foundation model for 3d computed tomography. Res Square. 2024. https://doi.org/10.21203/rs.3.rs-4546309/v1.
Article
Google Scholar
Li H, Liu H, Hu D, Wang J, Oguz I, editors. Promise: prompt-driven 3D medical image segmentation using pretrained image foundation models. In: 2024 IEEE international symposium on biomedical imaging (ISBI); 2024: IEEE. https://doi.org/10.1109/ISBI56570.2024.10635207.
Shi Y, Zhu X, Hu Y, Guo C, Li M, Wu J. Med-2E3: A 2D-enhanced 3D medical multimodal large language model. arXiv preprint arXiv:2411.12783. 2024. arXiv:2411.12783.
Zhou Z, Xia S, Shu M, Zhou H. Fine-grained abnormality detection and natural language description of medical CT images using large language models. Int J Innov Res Comput Sci Technol. 2024;12(6):52–62. https://doi.org/10.1109/ICHI61247.2024.00080.
Article
Google Scholar
Cherukuri TK, Shaik NS, Bodapati JD, Ye DH. GCS-M3VLT: guided context self-attention based multi-modal medical vision language transformer for retinal image captioning. arXiv preprint arXiv:2412.17251. 2024. arXiv:2412.17251.
Du J, Guo J, Zhang W, Yang S, Liu H, Li H, et al., editors. Ret-clip: a retinal image foundation model pre-trained with clinical diagnostic reports. In: International conference on medical image computing and computer-assisted intervention; 2024: Springer.
Luo Y, Shi M, Khan MO, Afzal MM, Huang H, Yuan S, et al. Fairclip: harnessing fairness in vision-language learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition; 2024.
Silva-Rodriguez J, Chakor H, Kobbi R, Dolz J, Ayed IB. A foundation language-image model of the retina (flair): encoding expert knowledge in text supervision. Med Image Anal. 2025;99:103357. https://doi.org/10.1016/j.media.2024.103357.
Article
Google Scholar
Wei H, Liu B, Zhang M, Shi P, Yuan W. VisionCLIP: an Med-AIGC based ethical language-image foundation model for generalizable retina image analysis. arXiv preprint arXiv:2403.10823. 2024. arXiv:2403.10823.
Yang S, Du J, Guo J, Zhang W, Liu H, Li H, et al. ViLReF: an expert knowledge enabled vision-language retinal foundation model. arXiv preprint arXiv:2408.10894. 2024. arXiv:2408.10894.
Li Z, Song D, Yang Z, Wang D, Li F, Zhang X, et al. VisionUnite: a vision-language foundation model for ophthalmology enhanced with clinical knowledge. arXiv preprint arXiv:2408.02865. 2024. arXiv:2408.02865.
Chen Q, Hong Y. Medblip: Bootstrapping language-image pre-training from 3d medical images and texts. In: Proceedings of the Asian conference on computer vision; 2024.
Wan Z, Liu C, Zhang M, Fu J, Wang B, Cheng S, Ma L, Quilodrán-Casas C, Arcucci R. Med-unic: unifying cross-lingual medical vision-language pre-training by diminishing bias. Adv Neural Inf Process Syst. 2023;36:56186–97.
Google Scholar
Xu Z, Chen C, Lu D, Sun J, Wei D, Zheng Y, et al. FM-ABS: promptable foundation model drives active barely supervised learning for 3D medical image segmentation. In: International conference on medical image computing and computer-assisted intervention; 2024: Springer. https://doi.org/10.1007/978-3-031-72111-3_28.
Ferber D, Wölflein G, Wiest IC, Ligero M, Sainath S, Ghaffari Laleh N, et al. In-context learning enables multimodal large language models to classify cancer pathology images. Nat Commun. 2024;15(1):10104. https://doi.org/10.1038/s41467-024-51465-9.
Article
Google Scholar
Vo HQ, Wang L, Wong KK, Ezeana CF, Yu X, Yang W, et al. Frozen large-scale pretrained vision-language models are the effective foundational backbone for multimodal breast cancer prediction. IEEE J Biomed Health Inform. 2024. https://doi.org/10.1109/JBHI.2024.3507638.
Article
Google Scholar
Christensen M, Vukadinovic M, Yuan N, Ouyang D. Vision–language foundation model for echocardiogram interpretation. Nat Med. 2024. https://doi.org/10.1038/s41591-024-02959-y.
Article
Google Scholar
Guo X, Chai W, Li S-Y, Wang G, editors. LLaVA-ultra: large Chinese language and vision assistant for ultrasound. In: Proceedings of the 32nd ACM international conference on multimedia; 2024. https://doi.org/10.1145/3664647.3681584.
Schmidgall S, Cho J, Zakka C, Hiesinger W. GP-VLS: a general-purpose vision language model for surgery. arXiv preprint arXiv:2407.19305. 2024. 10.48550/arXiv:2407.19305.
Lin B, Xu Y, Bao X, Zhao Z, Zhang Z, Wang Z, et al. SkinGEN: an explainable dermatology diagnosis-to-generation framework with interactive vision-language models. arXiv preprint

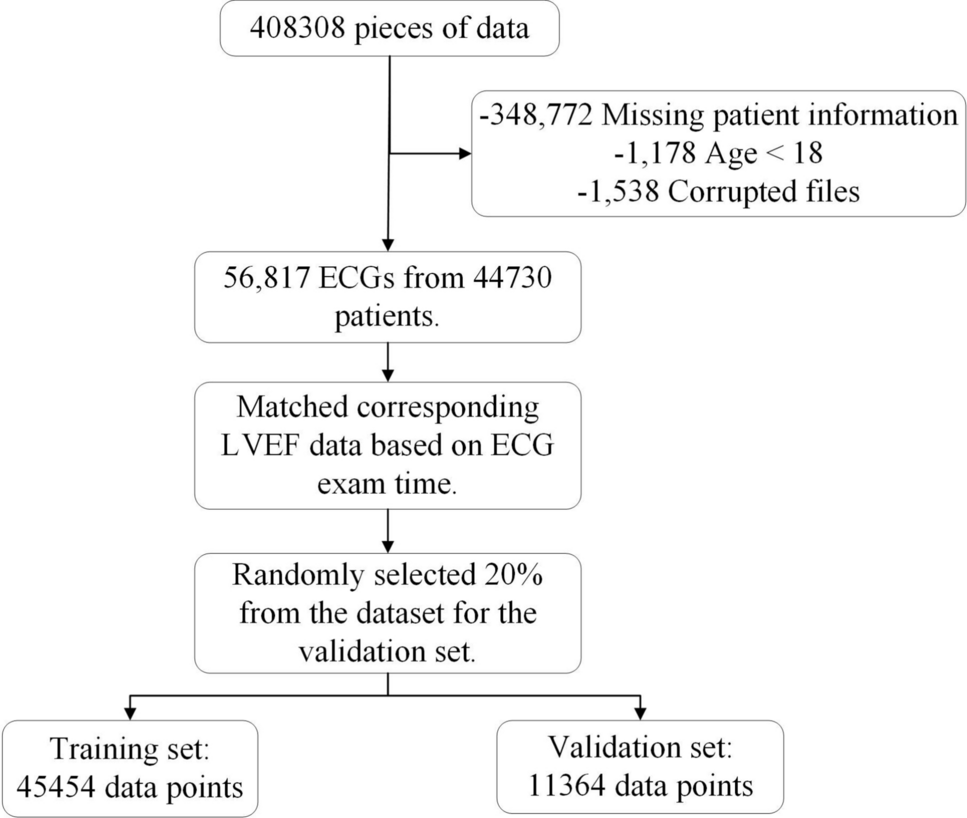


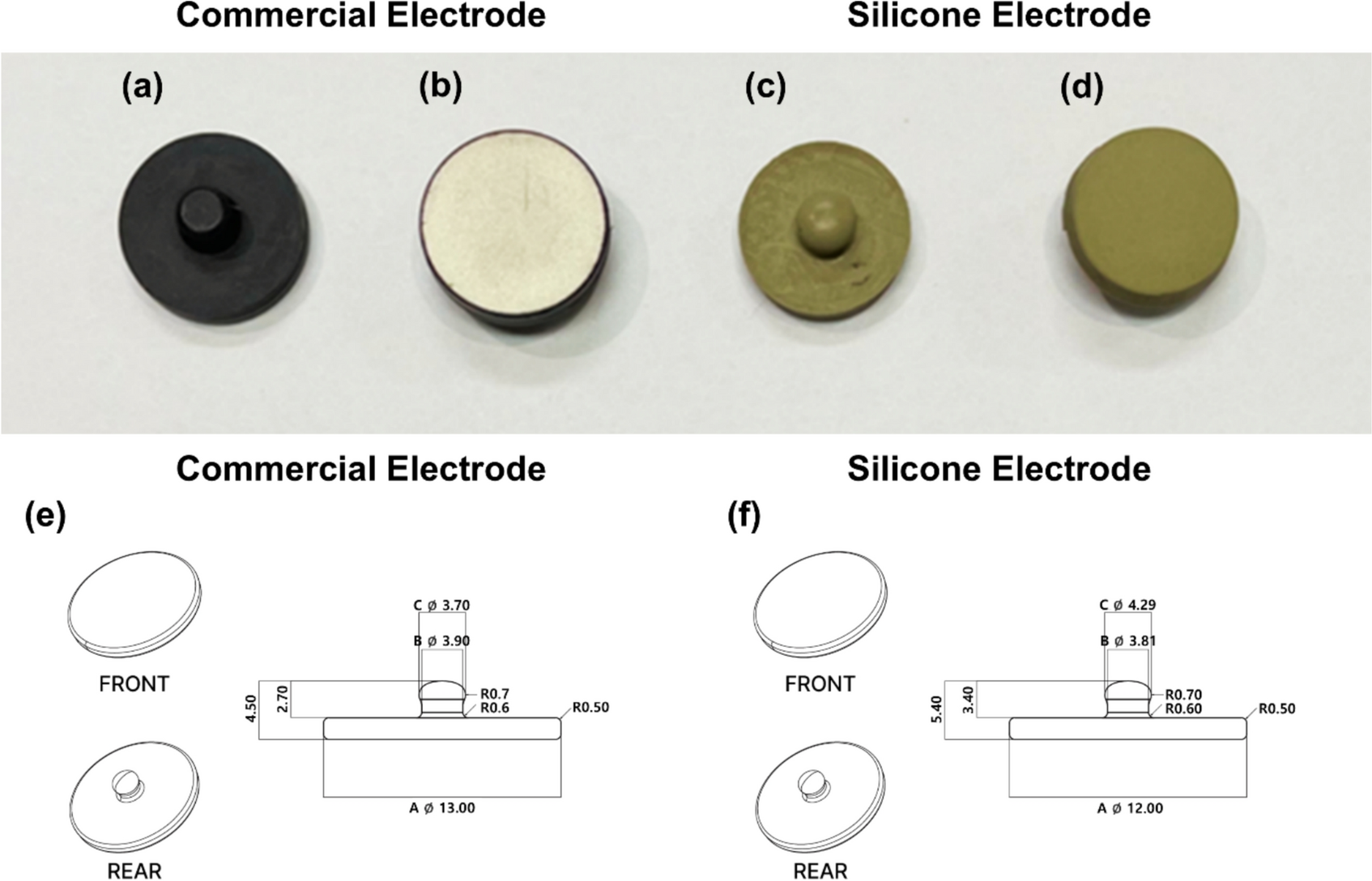
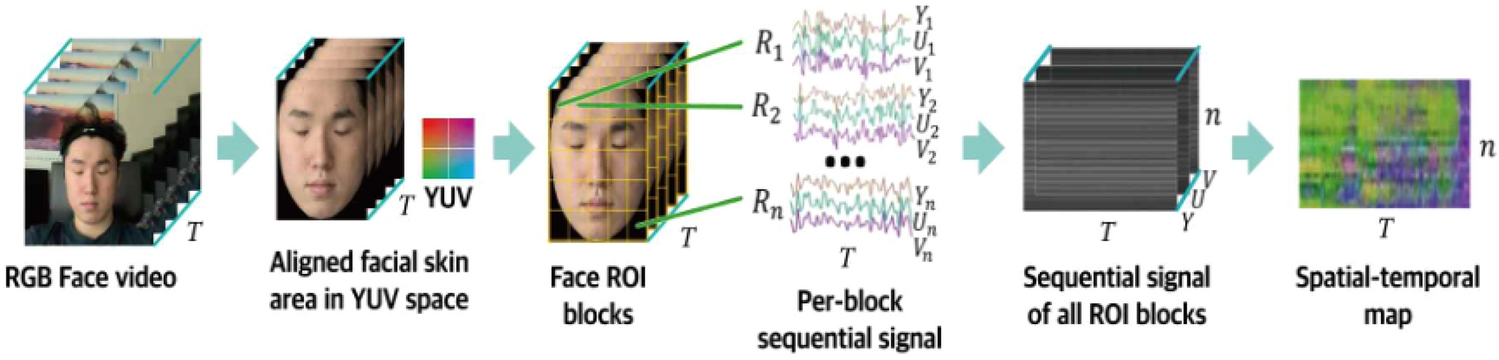
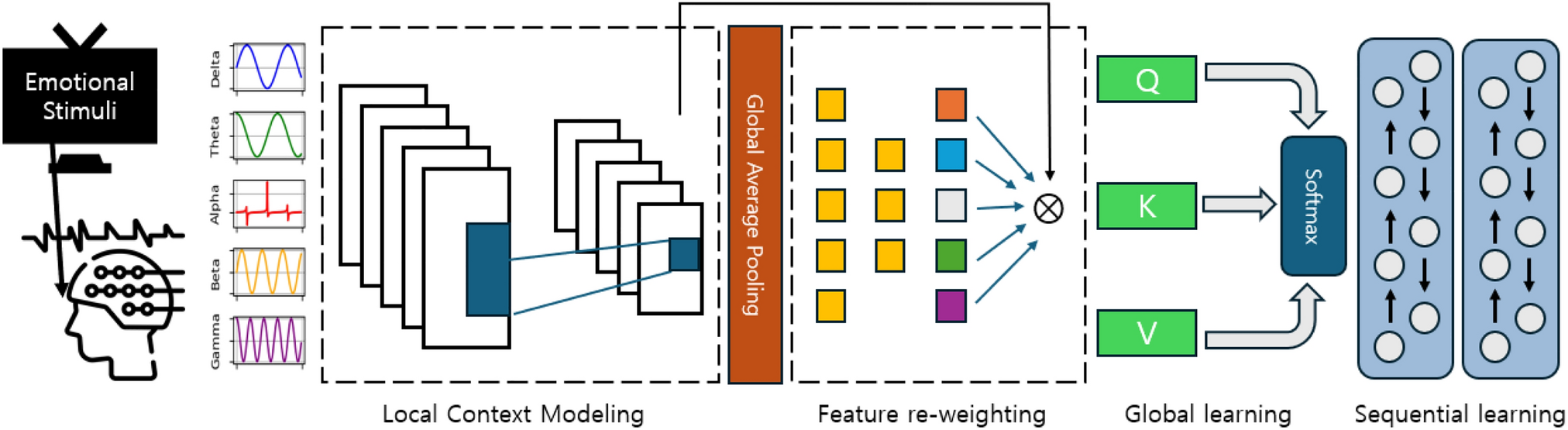

Comments (0)