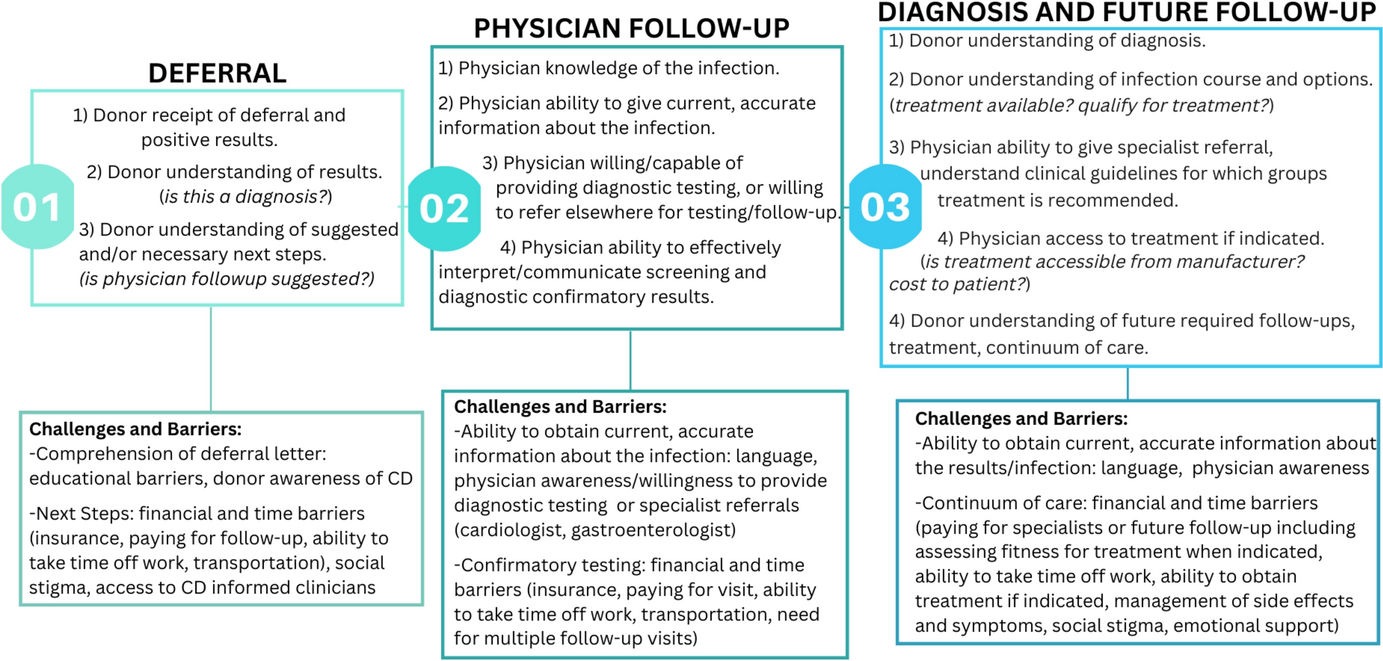
On 30 December 2015 at 21:22, Richard Baird, senior advisor to Michigan Governor Rick Snyder, wrote privately to Harvey Hollins, Director of Urban Initiatives, telling him, "Please don't confuse engagement with leadership. We will guarantee engagement and partnership. We do not to [sic] syndicate leadership" [11]. This private conversation was in response to Hollins’s public support of city and county leadership roles on Baird's newly proposed Flint Water Crisis Inter-Agency Coordinating Committee tasked with taking charge of the public health interventions in Flint.
Baird, along with Michigan State Police Chief Chris Kelenske, sought to centralize control among state officials. In their view, Flint officials could be “engaged,” but leadership and decision-making should remain in state hands. Hollins and others defended Flint’s right to a leadership seat but also shared doubts about who would be fit to serve. Hollins wrote: “We’ll have to work on the city piece because other than the Mayor or, Brian Larkin, there’s not one person I’d recommend” [12]. Nowhere in the conversation was it suggested that Flint should appoint its own representatives—the decision on the table was whether to even extend an invitation.
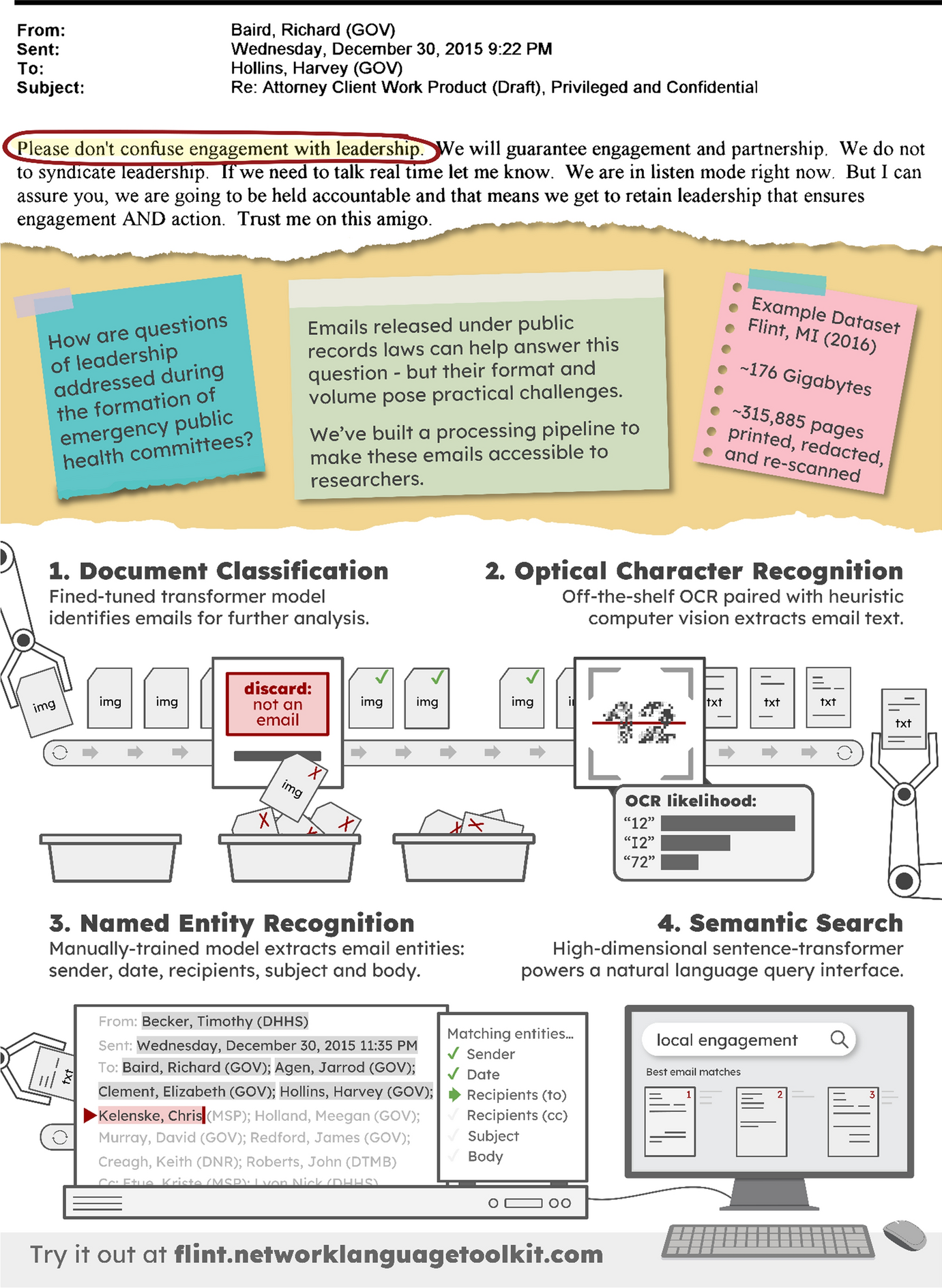
The above reconstruction provides a glimpse into the complex dynamics that shape the translation of public health policy into responses by government officials. Although we found the first email by chance while testing our search functionality, satisfying our desire to discover related emails meant assessing more than 315,000 candidate images released under Flint-related public records requests. The two emails cited [11, 12] appear ~ 1500 images apart in the dataset. Linking these emails would have been impractical without a pipeline of free and open-source data science tools to classify, extract, process and analyze the correspondence data. The supplemental material provides an overview of these specific tools and their licenses.
When researchers download a public records dataset, they will often find little more than a folder of sequentially named images of scanned documents. Documents can be of any type relevant to the scope of the records request (like spreadsheets, presentations, handwritten meeting notes). At scale, sorting through these images to find the document type of interest (like emails) is often impractical without automated document classification (Fig. 1, label 1). The supplemental material describes how we trained and evaluated a model for this task and provides examples of the types of documents found in the Flint dataset.
After the documents of interest are classified, extracting information from the images can begin (Fig. 1, label 2). In the case of emails, we extracted text from the images using an optical character recognition (OCR) model. The supplemental material describes a minor parameter change we made to allow the model to work well with emails.
The information extracted from images often requires further processing (Fig. 1, label 3). In our case, the OCR model had left us with unstructured email text, from which we ultimately wanted to identify the sender, date, recipient, subject and body, so that we could reconstruct the history of communication. The supplemental material details how we accomplished this by training an email-specific Named Entity Recognition (NER) model on a portion of our dataset.
Once classification, extraction, and processing are complete, analysis can proceed (Fig. 1, label 4). In our case, the entry point for analysis was the discovery of relevant conversations from our collection of processed emails. To accomplish this, we developed an interactive semantic search interface, as elaborated in the supplementary material.



Comments (0)