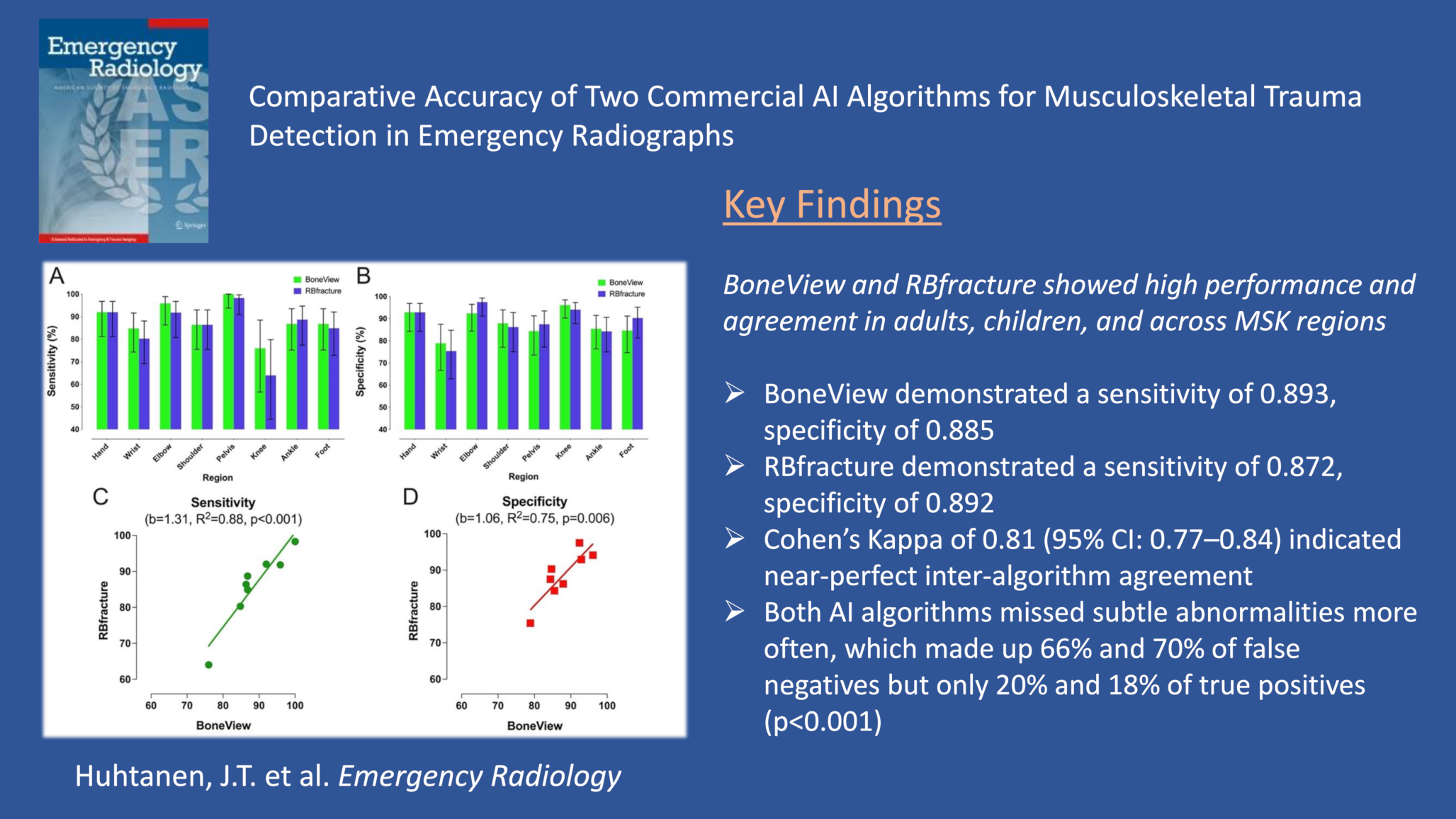
The purpose of this study was to compare the diagnostic performance of two commercially available AI algorithms, BoneView and RBfracture, in detecting acute trauma from MSK radiographs. BoneView demonstrated a sensitivity of 0.893, specificity of 0.885, and accuracy of 0.889, whereas RBfracture demonstrated a sensitivity of 0.872, specificity of 0.892, and accuracy of 0.884. There were no significant differences between AI algorithms, and there was almost a perfect agreement between them. These findings suggest acceptable diagnostic accuracy across multiple MSK regions and age groups and high consistency between AI algorithms, highlighting the potential benefit of using AI in acute trauma detection in emergency radiographs.
Both commercially available AI algorithms demonstrated high sensitivity and specificity in our dataset, including pediatric and adult patients and all relevant MSK regions. Our results are closely aligned with a recent meta-analysis reporting a pooled sensitivity of 0.91 (0.86–0.94) and a specificity of 0.89 (0.86–0.92) in fracture detection [2]. BoneView and RBfracture, with sensitivities of 0.893 and 0.872 and specificities of 0.885 and 0.892, respectively, remain within expected and acceptable performance for a stand-alone AI. In addition, our results are reasonably closely aligned with those from another meta-analysis showing AI sensitivity and specificity from external validations of 0.91 and 0.91, respectively [31]. BoneView is one of the most studied AI algorithms, and our study showed performance comparable with previous studies [2]. Both AI algorithms performed comparably to reported human ranges [32]. The combined performance of the two AI algorithms increased sensitivity but decreased specificity compared to the individual algorithms. Although deploying two algorithms for the same task may not be clinically reasonable, this approach might maximize sensitivity.
In our study, both AI algorithms tended to give more false positive predictions than false negatives, consistent with previous studies [15, 33, 34]. Although comparing the number of FP between different studies is challenging due to inherent variability in study designs, the amount of FP in our study is similar to those previously reported [15]. In addition, AI algorithms in this study made FP errors for reasons also shown in previous studies, including normal skeletal growth appearance or growth plate [15], old traumatic findings [19, 24], calcification [24, 25], and bone overlay [24]. Both AI algorithms occasionally missed obvious findings, but most missed findings were classified as subtle, consistent with previous studies [10, 17, 20,21,22]. The rigorous ground truth criteria applied by two experienced MSK specialists may account for some of the false negatives in our study. In addition, our study showed lower sensitivity but similar specificity values and lower PPV, but higher NPV compared to a previous study including all MSK regions [24]. In contrast to our study, Dell’Aria et al. 2024 included only 101 patients, resulting in a smaller dataset for specific MSK regions, and their study was limited to adult patients [24].
Although numerically somewhat lower, the sensitivity and specificity were not statistically significantly lower in children than in adults for either BoneView or RBfracture. Previous studies in AI’s pediatric interpretation have reported higher [15, 23] or similar [35, 36] values in sensitivity and in specificity [15, 23]. In contrast, Gleamer showed higher specificity values compared to per-patient specificity reported by Franco et al. 2024 [35]. In our study, the upper age limit for the children group was 17 years, whereas in the other study [36], it exceeded 17 years, and our study had fewer patients in the children group [15, 23, 35, 36], which can impact results. In addition, our study showed comparable sensitivity and specificity values for both AI algorithms compared to Oppenheimer et al. 2023 although they only had 31 patients in the children group [17]. Both AI algorithms displayed lower PPV in children than in adults, which may have been caused by the lower prevalence of trauma in children in the study sample.
AI algorithm performance varied between MSK regions. The lowest sensitivity values for BoneView and RBfracture were in the knee interpretation, at 0.760 and 0.640, respectively. This contrasts with previous findings [2, 17], possibly due to a low number of abnormal knee cases in our study. Low sensitivity values and wide variation in knee performance were also reported by a recent meta-analysis [2]. Conversely, the specificity values for BoneView and RBfracture were similar than those previously reported [2, 17]. In the pelvis, both AI algorithms displayed excellent sensitivity values, with higher [17, 33] or similar values compared to the pooled sensitivity in a recent meta-analysis [2, 37, 38] and individual studies [20, 34, 39, 40], while specificities are at similar levels [2, 17, 20, 33, 37,38,39] or slightly lower than those previously reported [34]. In the pelvis, comparing different studies is challenging, as some have focused on specific findings, such as femoral neck fractures, whereas we included the whole pelvis. Both AI algorithms had comparable sensitivity and specificity levels compared to a recent meta-analysis for ankle and foot [2, 17].
Shoulder interpretation showed similar results to a meta-analysis, where sensitivity and specificity fall within the meta-analytical confidence intervals [2]. In addition, other studies have also demonstrated similar sensitivity and specificity values [17, 25]. For elbow interpretation, our study demonstrated strong performance, with sensitivity and specificity values of 0.959 and 0.924 for BoneView and 0.918 and 0.975 for RBfracture, respectively, compared to previous findings [2, 17]. Relative to previous meta-analytic findings [8, 41], we found similar results in the wrist in sensitivity and specificity values for both AI algorithms. In contrast, previous individual studies showed higher sensitivity values compared to RBfracture [42] or both BoneView and RBfracture [43] but similar specificities [42, 43]. Jacques et al. 2023 demonstrated more modest sensitivity values in wrist interpretation, although the values fall within confidence intervals in our study, and they used CT as the ground truth, which can affect the comparison [44]. In addition, they also included findings in the hand, which makes the comparison difficult. The hand showed higher overall values in our study compared to the wrist, although the CIs overlapped. In our study, wrist had more abnormal than normal findings defined by the ground truth, which can impact the results. In the recent meta-analysis [8, 41], the ground truth varied, including radiologists, orthopedic surgeons, and radiology residents, or original reports checked by a resident with various experience levels, which can also affect the comparison. Furthermore, some studies included only specific fractures, such as distal radius fractures [43], rather than all traumatic findings, which is noteworthy given AI’s limited performance in detecting carpal bone fractures, for example [44, 45]. In our study, many false negatives by the AI algorithms in wrist radiographs were related to carpal instability findings, such as scapholunate interval widening or dorsal intercalated segmental instability (DISI). This suggests that these AI algorithms struggle to detect such subtle findings.
Some limitations of the current study warrant discussion. First, by including all relevant MSK regions, the number of cases in each region was limited. Second, potential bias in the ground truth, defined as the consensus of the subjective views of two experienced MSK specialists, may affect the result. Additionally, we did not re-evaluate the FP findings from AI algorithms, which precludes further insights on the limits of AI performance. Third, AI findings were categorized as normal or abnormal without assessing the size or location of bounding boxes, and the ground truth did not include bounding boxes at the site of findings. Neither did the ground truth include the types of abnormalities, which may limit our results in specific scenarios, such as occult fractures, dislocations, or specific fractures for pediatric patients which are more difficult to interpret in radiographs. Fourth, an AI interpretation was classified as correctly abnormal (TP) even if one of multiple fractures was missed. Fifth, using computed tomography (CT) or magnetic resonance imaging (MRI) as ground truth might be preferred. Sixth, secondary findings, like joint effusion, were not classified in this study, and these cases were classified as normal, in the absence of a fracture or a dislocation.
Based on these results, directions for future studies may be considered. Using cross-sectional imaging (CT or MRI) as the reference standard might provide further insights. Different types of fractures and dislocations should be recorded to give more granular information about AI performance. The sample sizes should be large enough to provide adequate statistical power to assess performance across different MSK regions, specific types of trauma, chronic deformities, and doubtful or borderline cases. Finally, prospective studies on AI deployment in the emergency department would be preferred to gauge additional factors, such as patient and referring physician satisfaction and improvement of workflows.

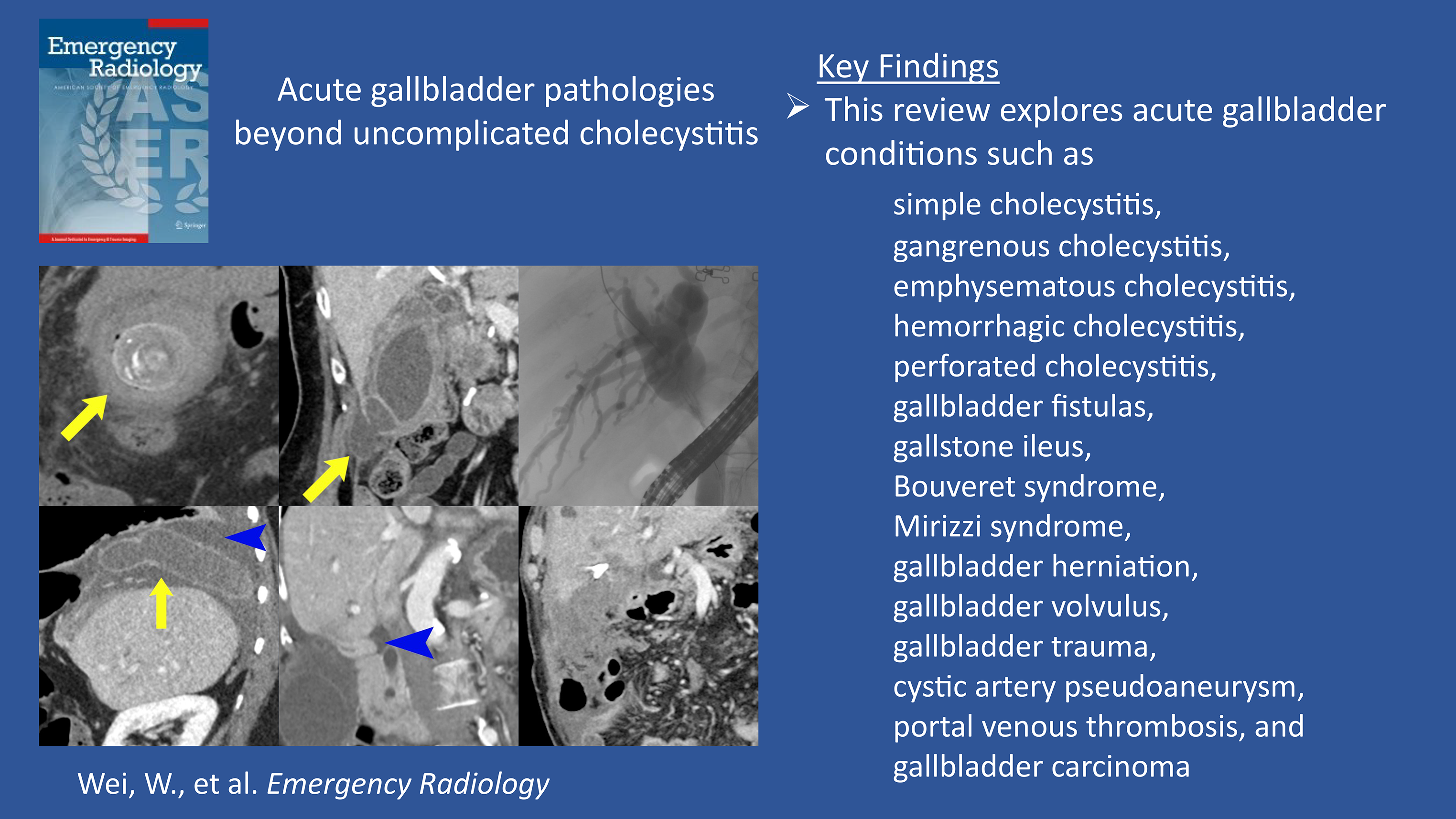








Comments (0)