Guo E, Gupta M, Deng J, Park YJ, Paget M, Naugler C. Automated paper screening for clinical reviews using large language models: data analysis study. J Med Internet Res. 2024;26: e48996. https://doi.org/10.2196/48996.
Article
PubMed
PubMed Central
Google Scholar
Fleurence R, Bian J, Wang X, Xu H, Dawoud D, Higashi M, et al. Generative AI for health technology assessment: opportunities, challenges, and policy considerations. arXiv. 2024; https://doi.org/10.48550/arXiv.2407.11054.
Reason T, Benbow E, Langham J, Gimblett A, Klijn SL, Malcolm B. Artificial intelligence to automate network meta-analyses: four case studies to evaluate the potential application of large language models. Pharmacoecon Open. 2024;8:205–20. https://doi.org/10.1007/s41669-024-00476-9.
Article
PubMed
PubMed Central
Google Scholar
Reason T, Rawlinson W, Langham J, Gimblett A, Malcolm B, Klijn S. Artificial intelligence to automate health economic modelling: a case study to evaluate the potential application of large language models. Pharmacoecon Open. 2024;8:191–203. https://doi.org/10.1007/s41669-024-00477-8.
Article
PubMed
PubMed Central
Google Scholar
Reason T, Langham J, Gimblett A. Automated mass extraction of over 680,000 PICOs from clinical study abstracts using generative AI: a proof-of-concept study. Pharmaceut Med. 2024;38:365–72. https://doi.org/10.1007/s40290-024-00539-6.
Article
PubMed
PubMed Central
Google Scholar
Adamson B, Waskom M, Blarre A, Kelly J, Krismer K, Nemeth S, et al. Approach to machine learning for extraction of real-world data variables from electronic health records. Front Pharmacol. 2023. https://doi.org/10.3389/fphar.2023.1180962.
Article
PubMed
PubMed Central
Google Scholar
OpenAI. OpenAI developer platform. 2024. https://platform.openai.com/docs/overview. Accessed 3 Sep 2024.
Anthropic. Welcome to Claude. 2024. https://docs.anthropic.com/en/docs/welcome. Accessed 3 Sep 2024.
Meta. Resources and tools for advancing AI, together. 2024. https://ai.meta.com/resources/. Accessed 3 Sep 2024.
Python Package Index. Transformers 4.46.1. 2024. https://pypi.org/project/transformers/. Accessed 5 Nov 2024.
LangChain. Introduction v0.3. 2024. https://python.langchain.com/docs/introduction/. Accessed 5 Nov 2024.
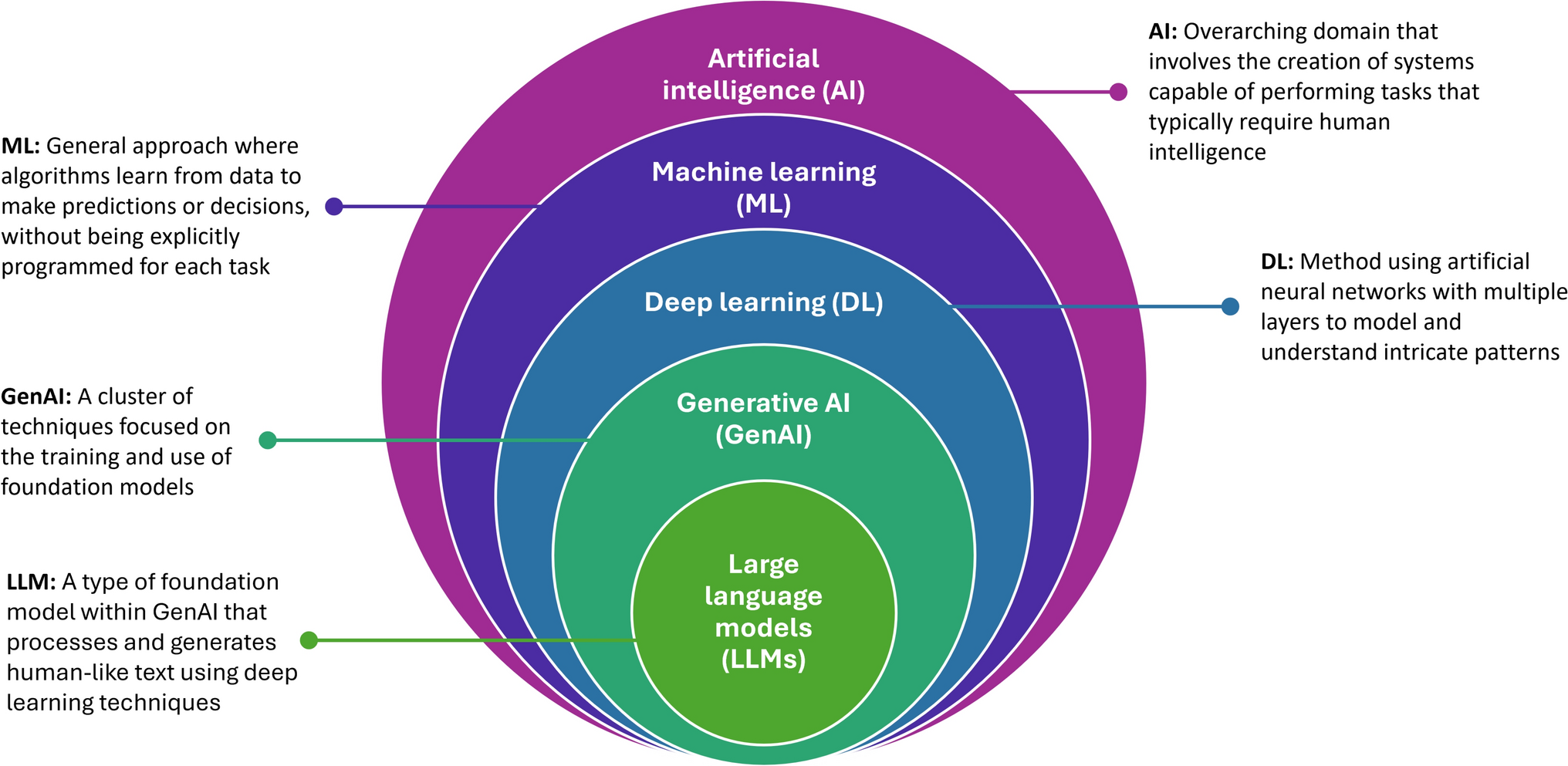
IBM. AI vs. machine learning vs. deep learning vs. neural networks: What’s the difference? 2023. https://www.ibm.com/think/topics/ai-vs-machine-learning-vs-deep-learning-vs-neural-networks. Accessed 25 Oct 2024.
IBM. What are foundation models? 2024. https://www.ibm.com/think/topics/foundation-models. Accessed 11 Nov 2024.
IBM. What are large language models (LLMs)? 2024. https://www.ibm.com/topics/large-language-models. Accessed 11 Nov 2024.
Google for Developers. Introduction to large language models. 2024. https://developers.google.com/machine-learning/resources/intro-llms. Accessed 11 Nov 2024.
ChatGPT. ChatGPT: Get started. 2024. https://chatgpt.com/auth/login. Accessed 23 Sep 2024.
Qwen Team. Qwen2.5: A party of foundation models! 2024. https://qwenlm.github.io/blog/qwen2.5/. Accessed 3 Oct 2024.
Tardif A. Llama 3.1: Meta’s most advanced open-source ai model—everything you need to know. 2024. https://www.unite.ai/llama-3-1-metas-most-advanced-open-source-ai-model-everything-you-need-to-know/. Accessed 12 Aug 2024.
Pourpanah F, Abdar M, Luo Y, Zhou X, Wang R, Lim CP, et al. A review of generalized zero-shot learning methods. IEEE Trans Pattern Anal Mach Intell. 2023;45:4051–70. https://doi.org/10.1109/tpami.2022.3191696.
Article
PubMed
Google Scholar
Ge Y, Guo Y, Das S, Al-Garadi MA, Sarker A. Few-shot learning for medical text: a review of advances, trends, and opportunities. J Biomed Inform. 2023;144: 104458. https://doi.org/10.1016/j.jbi.2023.104458.
Article
PubMed
PubMed Central
Google Scholar
Lu J, Jin S, Liang J, Zhang C. Robust few-shot learning for user-provided data. IEEE Trans Neural Netw Learn Syst. 2021;32:1433–47. https://doi.org/10.1109/tnnls.2020.2984710.
Article
PubMed
Google Scholar
OpenAI. Hello GPT-4o. 2024. https://openai.com/index/hello-gpt-4o/. Accessed 13 Aug 2024.
Anthropic. Meet Claude 3.5 Sonnet. 2024. https://www.anthropic.com/claude. Accessed 13 Aug 2024.
Meta. Meet Llama 3.1. 2024. https://llama.meta.com/. Accessed 13 Aug 2024.
Google. Gemini: Supercharge your creativity and productivity. 2024. https://gemini.google.com/. Accessed 13 Aug 2024.
Spheron. Choosing the right LLM: 2024 comparison of open-source vs closed-source LLMs. 2024. https://blog.spheron.network/choosing-the-right-llm-2024-comparison-of-open-source-vs-closed-source-llms. Accessed 27 Jan 2025.
Razzaq A. Llama 3.1 vs GPT-4o vs Claude 3.5: A comprehensive comparison of leading AI models. 2024. https://www.marktechpost.com/2024/07/27/llama-3-1-vs-gpt-4o-vs-claude-3-5-a-comprehensive-comparison-of-leading-ai-models/. Accessed 13 Aug 2024.
Artificial Analysis. Independent analysis of AI models and API providers. 2024. https://artificialanalysis.ai/. Accessed 13 Aug 2024.
Artificial Analysis. LLM leaderboard - comparison of GPT-4o, Llama 3, Mistral, Gemini and over 30 models. 2025. https://artificialanalysis.ai/leaderboards/models. Accessed 10 Feb 2025.
Liu A, Feng B, Xue B, Wang B, Wu B, Lu C, et al. Deepseek-v3 technical report. arXiv. 2024;
Patel D, Kourabi AJ, O'Laughlin D, Knuhtsen R. DeepSeek Debates: Chinese Leadership On Cost, True Training Cost, Closed Model Margin Impacts. 2025. https://semianalysis.com/2025/01/31/deepseek-debates/. Accessed Mar 25 2025.
Swartz J. Early Critic of DeepSeek Says Model Cost Was $1.6 Billion, Not $5.6 Million. 2025. https://techstrong.ai/agentic-ai/early-critic-of-deepseek-says-model-cost-was-1-6-billion-not-5-6-million/. Accessed 25 Mar 2025.
HYPE Studio. The definitive guide to open source large language models (LLMs). 2024. https://hypestudio.org/blog/guide-to-open-source-large-language-models/. Accessed 11 Nov 2024.
Huang D, Yan C, Li Q, Peng X. From large language models to large multimodal models: a literature review. Appl Sci. 2024;14 https://doi.org/10.3390/app14125068.
Wang J, Jiang H, Liu Y, Ma C, Zhang X, Pan Y, et al. A comprehensive review of multimodal large language models: Performance and challenges across different tasks. arXiv. 2024; https://doi.org/10.48550/arXiv.2408.01319.
Cremonesi F, Planat V, Kalokyri V, Kondylakis H, Sanavia T, Miguel Mateos Resinas V, et al. The need for multimodal health data modeling: A practical approach for a federated-learning healthcare platform. J Biomed Inform. 2023;141:104338. https://doi.org/10.1016/j.jbi.2023.104338.
Artsi Y, Sorin V, Glicksberg BS, Nadkarni GN, Klang E. Advancing Clinical Practice: The Potential of Multimodal Technology in Modern Medicine. J Clin Med. 2024;13 https://doi.org/10.3390/jcm13206246.
Microsoft. Microsoft 365 Copilot documentation. 2024. https://learn.microsoft.com/en-us/copilot/microsoft-365/. Accessed 23 Sep 2024.
Gordon WJ, Rudin RS. Why APIs? Anticipated value, barriers, and opportunities for standards-based application programming interfaces in healthcare: perspectives of US thought leaders. JAMIA Open. 2022;5 https://doi.org/10.1093/jamiaopen/ooac023.
IBM. What is an API (application programming interface)? 2024. https://www.ibm.com/topics/api. Accessed 9 Sep 2024.
Smith RA, Schneider PP, Mohammed W. Living HTA: Automating health economic evaluation with R. 2022. https://wellcomeopenresearch.org/articles/7-194. Accessed 11 Jan 2025.
OpenAI. Key concepts to understand when working with the OpenAI API [Tokens]. 2024. https://platform.openai.com/docs/concepts#tokens. Accessed 24 Jul 2024.
Ramponi M. Decoding strategies: how LLMs choose the next word. 2024. https://www.assemblyai.com/blog/decoding-strategies-how-llms-choose-the-next-word/. Accessed 3 Oct 2024.
Burtell M, Toner H. The Surprising Power of Next Word Prediction: Large Language Models Explained, Part 1. 2024. https://cset.georgetown.edu/article/the-surprising-power-of-next-word-prediction-large-language-models-explained-part-1/. Accessed 3 Oct 2024.
Mehdi Y. Reinventing search with a new AI-powered Microsoft Bing and Edge, your copilot for the web. 2023. https://blogs.microsoft.com/blog/2023/02/07/reinventing-search-with-a-new-ai-powered-microsoft-bing-and-edge-your-copilot-for-the-web/. Accessed 24 Jul 2024.
Wu Y, Zhang J, Hu N, Tang L, Qi G, Shao J, et al. MLDT: Multi-level decomposition for complex long-horizon robotic task planning with open-source large language model. arXiv. 2024; https://doi.org/10.48550/arXiv.2403.18760.
Prasad A, Koller A, Hartmann M, Clark P, Sabharwal A, Bansal M, et al. Adapt: As-needed decomposition and planning with language models. arXiv. 2023; https://doi.org/10.48550/arXiv.2311.05772.
Li J, Deng Y, Sun Q, Zhu J, Tian Y, Li J, et al. Benchmarking large language models in evidence-based medicine. IEEE J Biomed Health Inform. 2024;Pp https://doi.org/10.1109/jbhi.2024.3483816.
Rawlinson W, Klijn S, Teitsson S, Malcolm B, Gimblett A, Reason T. Automating economic modelling: potential of generative AI for updating excel-based cost-effectiveness models. Value Health. 2024;27:S11. https://doi.org/10.1016/j.jval.2024.03.074; poster available at https://www.ispor.org/docs/default-source/intl2024/ee205-upload-version138660-pdf.pdf?sfvrsn=df5c4356_0. .
Xu W, Lan Y, Hu Z, Lan Y, Lee RK-W, Lim E-P. Plan-and-solve prompting: improving zero-shot chain-of-thought reasoning by large language models. Poster 7806 presented at the NeurIPS, New Orleans, USA, 10–Dec. 2023. https://openreview.net/attachment?id=5Xc1ecxO1h&name=pdf. Accessed 14 Feb 2025.
Hebenstreit K, Praas R, Kiesewetter LP, Samwald M. A comparison of chain-of-thought reasoning strategies across datasets and models. PeerJ Comput Sci. 2024;10: e1999. https://doi.org/10.7717/peerj-cs.1999.
Article
PubMed
PubMed Central
Google Scholar
Hu B, Zhu J, Pei Y, Gu X. Exploring the potential of LLM to enhance teaching plans through teaching simulation. NPJ Sci Learn. 2025;10:7. https://doi.org/10.1038/s41539-025-00300-x.
Article
PubMed
PubMed Central
Google Scholar
Liang W, Zhang Y, Cao H, Wang B, Ding DY, Yang X, et al. Can large language models provide useful feedback on research papers? A large-scale empirical analysis. NEJM AI. 2024;1:Aloa2400196. https://doi.org/10.1056/AIoa2400196.
Article
Google Scholar
Zaghir J, Naguib M, Bjelogrlic M, Névéol A, Tannier X, Lovis C. Prompt engineering paradigms for medical applications: scoping review and recommendations for better practices. arXiv. 2024; https://doi.org/10.48550/arXiv.2405.01249.
Lewis P, Perez E, Piktus A, Petroni F, Karpukhin V, Goyal N, et al. Retrieval-augmented generation for knowledge-intensive NLP Tasks. arXiv. 2020; https://doi.org/10.48550/arXiv.2005.11401.
Liu S, McCoy AB, Wright A. Improving large language model applications in biomedicine with retrieval-augmented generation: a systematic review, meta-analysis, and clinical development guidelines. J Am Med Inform Assoc. 2025. https://doi.org/10.1093/jamia/ocaf008.
Article
PubMed
PubMed Central
Google Scholar
OpenAI. Reasoning models. 2024. https://platform.openai.com/docs/guides/reasoning?reasoning-prompt-examples=coding-planning. Accessed 3 Oct 2024.
Chen B, Zhang Z, Langrené N, Zhu S. Unleashing the potential of prompt engineering in large language models: a comprehensive review. arXiv. 2023; https://doi.org/10.48550/arXiv.2310.14735.
Wei J, Wang X, Schuurmans D, Bosma M, Xia F, Chi E, et al. Chain-of-thought prompting elicits reasoning in large language models. Adv Neural Inf Process Syst. 2022;35:24824–37.
Google Scholar
Kojima T, Gu SS, Reid M, Matsuo Y, Iwasawa Y. Large language models are zero-shot reasoners. Poster 706 presented at the NeurIPS, Virtual & New Orleans, USA, 28 Nov–9 Dec. 2022. https://neurips.cc/virtual/2022/poster/54287. Accessed 14 Feb 2025.
Wei J, Wang X, Schuurmans D, Bosma M, Chi EH, Xia F, et al. Chain of thought prompting elicits reasoning in large language models. arXiv. 2022; https://doi.org/10.48550/arXiv.2201.11903.
Yao S, Yu D, Zhao J, Shafran I, Griffiths T, Cao Y, et al. Tree of thoughts: Deliberate problem solving with large language models. Poster presented at the Advances in Neural Information Processing Systems. 2024. Accessed 14 Feb 2025.
GitHub. What is retrieval-augmented generation, and what does it do for generative AI? 2024. https://github.blog/ai-and-ml/generative-ai/what-is-retrieval-augmented-generation-and-what-does-it-do-for-generative-ai/. Accessed 6 Nov 2024.
OWASP. OWASP Application Security Verification Standard (ASVS). 2024. https://owasp.org/www-project-application-security-verification-standard/. Accessed 6 Nov 2024.
Wang X, Wei J, Schuurmans D, Le Q, Chi E, Narang S, et al. Self-consistency improves chain of thought reasoning in language models. arXiv. 2022; https://doi.org/10.48550/arXiv.2203.11171.
Ratwani RM, Sutton K, Galarraga JE. Addressing AI algorithmic bias in health care. JAMA. 2024;332:1051–2. https://doi.org/10.1001/jama.2024.13486.
Article
PubMed
Google Scholar
Radeva D, Hopkin G, Mossialos E, Borrill J, Osipenko L, Naci H. Assessment of technical errors and validation processes in economic models submitted by the company for NICE technology appraisals. Int J Technol Assess Health Care. 2020;36:311–6.
Article
Google Scholar
Chi W-C, Lin P-J, Chang IC, Chen S-L. The inhibiting effects of resistance to change of disability determination system: a status quo bias perspective. BMC Med Inform Decis Mak. 2020;20:82. https://doi.org/10.1186/s12911-020-1090-7.
Article
PubMed



Comments (0)