
Remember me
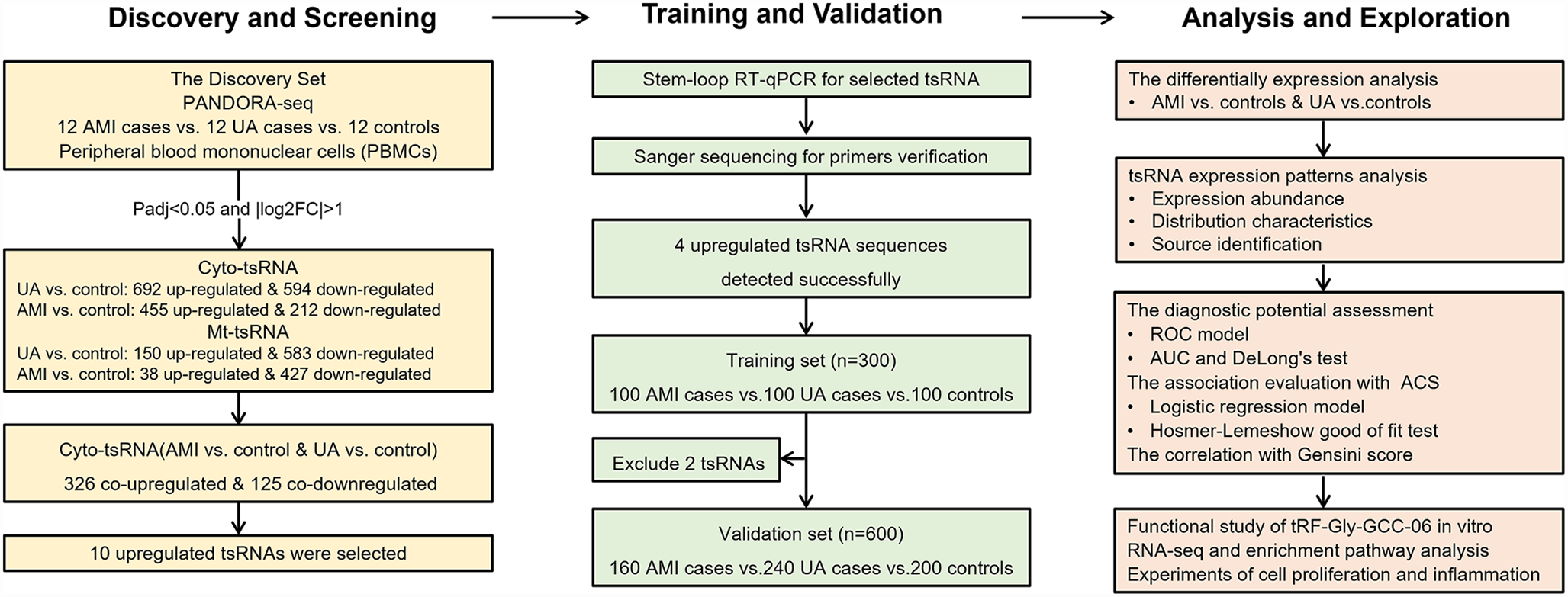
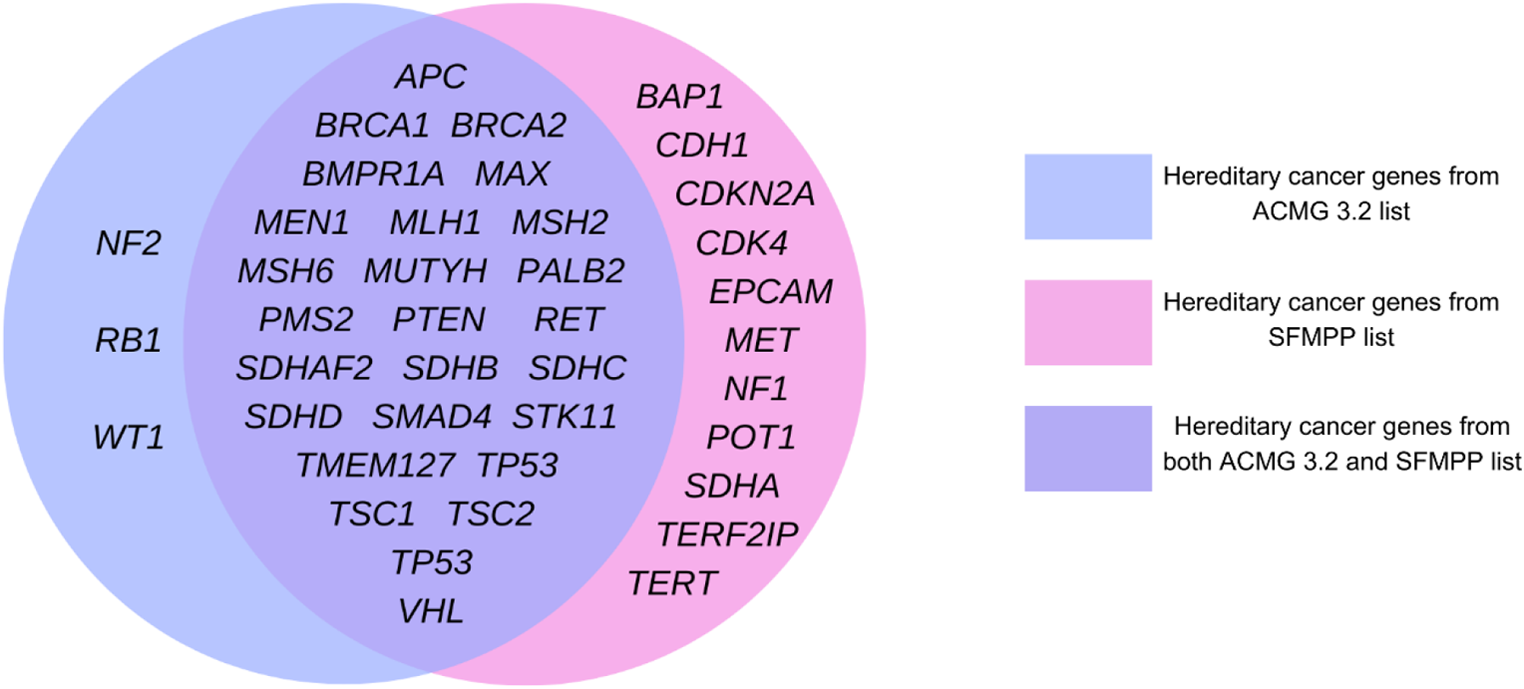



The methodology is summarized in Fig. 1. Dataset preparation, which included filtering, preprocessing, and annotation, was performed using an in-house customized pipeline written in Perl on Linux. The model development and evaluation were conducted using Python on the Google Colab platform. Canonical transcripts were used to annotate variants under the GRCh38 reference assembly.
Fig. 1
The flowchart of the PRP. Data preparation and model development and evaluation
Training datasetThe training dataset was sourced from the ClinVar (Landrum et al. 2018) database (clinvar_20230826.vcf.gz), which comprises clinically observed genetic variants. ClinVar includes a wide range of variant types located not only in coding regions but also in non-coding regions, with well-curated classifications distinguishing pathogenic from benign variants. The variants were filtered based on the following criteria. First, nsSNVs, including missense, start_lost, stop_gained, and stop_lost variants in coding regions, were selected. Second, nsSNVs with the clinical significance classified as pathogenic, likely pathogenic, or pathogenic/likely pathogenic were labeled as true positives (TPs), while those classified as benign, likely benign, or benign/likely benign were labeled as true negatives (TNs). Third, to reduce false positives in the curated data, nsSNVs with the review status of practice guidelines, reviewed by an expert panel, or criteria provided multiple submitters, no conflicts were retained. After filtering, 47,883 nsSNVs remained, consisting of 26,383 TPs and 21,500 TNs. To improve the classification of rare variants, 3,000 rare TNs were randomly selected and added. These variants were chosen based on the same criteria up to the second one described above, with the review status of criteria provided by a single submitter and an AF of less than 3e-4. The AF of 3e-4 corresponds to the first quartile of AFs among the 21,500 TNs. Since the number of TNs with AFs below this value was substantially lower than that of TPs, 3,000 additional TN variants were selected to balance the two classes within this low-AF range. Ultimately, the training dataset comprised 50,883 nsSNVs, including 26,383 TPs and 24,500 TNs, originating from 4,596 genes. The variant types included in the training dataset consisted of 37,803 (74.29%) missense, 335 (0.66%) start_lost, 12,720 (25%) stop_gained, and 25 (0.05%) stop_lost variants (Table S1), and the dataset was used for model development.
Test datasetThree distinct test datasets were compiled to assess the performance and generalizability of the model. To avoid Type 1 circularity, where the model may overestimate its performance by using the same or highly similar data for both training and evaluation, variants in the test datasets that overlapped with the training dataset were excluded (Grimm et al. 2015). In addition, overlapping variants among the three test datasets were removed to ensure independence between datasets. Variants with conflicting clinical interpretations across datasets were also excluded to maintain consistency and reduce potential bias. Furthermore, to avoid potential overlap with the training datasets of other prediction tools, which were published by 2022 and constructed using data available before that year, variants that were newly registered in 2022 or later were selected as the test dataset.
Test Dataset 1 was obtained from the latest ClinVar data (clinvar_20231230.vcf.gz). by applying the same filtering criteria used for the training dataset, and nsSNVs overlapping with the training dataset were removed. This resulted in 4,920 nsSNVs, including 2,841 TPs and 2,079 TNs from 1,813 genes, being used. Test Dataset 2 was sourced from Humsavar (release 2022_05) in UniProt (Mottaz et al. 2010; The UniProt 2017), which consists solely of missense variants curated from the literature. Variants classified as LP/P (likely pathogenic or pathogenic) were retained as TPs, while those classified as LB/B (likely benign or benign) were retained as TNs. Variants overlapping with the training dataset and Test Dataset 1 were removed, and those registered before 2022 were excluded, yielding 13,127 nsSNVs, comprising 6,840 TPs and 6,287 TNs from 4,986 genes. Test Dataset 3 was obtained from the Clinical Genome Resource (ClinGen) (Rehm et al. 2015), which provides a centralized database for the evidence-based classification of variants, supporting precision medicine and clinical decision-making. ClinGen includes various variant types located in coding regions, with well-curated classifications distinguishing pathogenic from benign variants. First, nsSNVs were selected. Second, nsSNVs with the assertion categorized as pathogenic or likely pathogenic were retained as TPs, while those categorized as benign or likely benign were retained as TNs. Third, to ensure the independence of this dataset, nsSNVs that overlapped with the training dataset and other test datasets were removed, and only nsSNVs with the approval date after 2022 were included. This dataset consisted of 282 nsSNVs, comprising 239 TPs and 43 TNs from 37 genes. The number and proportion of variant types for each test dataset were listed in Table S1.
Dataset annotationThirty-four features from four categories were used to predict pathogenic variants, as listed in Supplementary Table S2.
First, frequencies related to allele frequency (AF), codon usage frequency (CF) of the codon containing the variant, and neighbor preference frequency (NPF) of amino acids adjacent to the variant were employed. AFs were obtained from gnomAD (Karczewski et al. 2020), covering all the exomes in versions 2 and 4. CF, which represents codon usage frequency in humans, was obtained from the Codon Statistics Database (Subramanian et al. 2022), which provides codon usage statistics for all species with reference or representative genomes in RefSeq. NPF was calculated using a human protein reference sequence from NCBI, applying the formula below (Xia and Xie 2002):
$$\:f\left(_\right)=\frac^\sum\:_^n\left(_\right)}_\right)}$$
where \(\:n\left(_\right)\) is the number of amino acids \(\:j\) in the protein reference sequence and \(\:n\left(_\right)\:\) is the number when the center amino acid is \(\:j\), the forward amino acid is \(\:i\) and the backward amino acid is \(\:k\). And \(\:_\) is amino acid triplets. Amino acids have distinct neighbor preferences, which influence their placement in different secondary structures. It is known that amino acids with similar neighbor preferences tend to substitute for one another more frequently than those with different preferences (Xia and Xie 2002). A higher NFP indicates similar neighbor preferences, while a lower NFP suggests differing preferences.
Second, conservation scores, including PhyloP (100way, 470way) (Pollard et al. 2010), PhastCons (100way, 470way) (Siepel et al. 2005), and multiz100way (exonNuc, exonAA), were obtained from UCSC (Kent et al. 2002). These scores were calculated based on the multiple sequence alignments of various species. PhyloP and PhastCons were utilized not only at the allele level but also at the codon, domain, and gene levels, where scores were averaged across these regions. The positions of the domains were obtained using the InterPro (Blum et al. 2021) API, and the gene structure was acquired from GenBank’s GFF file (Benson et al. 2013). The nucleotide and amino acid frequencies of the multiz100way were calculated using the formula below (Capriotti and Fariselli 2022):
$$\:f\left(_\right)=\frac_\right)}_^n\left(_\right)}$$
where \(\:n\left(_\right)\) is the number of the nucleotide or amino acid \(\:_\) in the sequence alignment and \(\:k\) is equal to 5 (including the generic nucleotide N) and 20 for DNA and protein sequences, respectively.
Third, substitution metrics included BLOSUM62 (Henikoff and Henikoff 1992), PAM250 (Dayhoff et al. 1978), and Grantham (Grantham 1974), as well as codon substitution (codonST) and amino acid substitution (aaST) (Shauli et al. 2021). BLOSUM62, PAM250, and Grantham are cross-species substitution metrics used to score the alignments between protein sequences. BLOSUM62 and PAM250 primarily focus on evolutionary distances, whereas Grantham assessed physiochemical differences based on the volume, polarity, and chemical properties of the side chains between amino acids. codonST and aaST are human-specific substitution metrics calculated using the ExAC database (Lek et al. 2016) and obtained from Tair et al (Shauli et al. 2021).
Lastly, gene intolerance scores, including pLI (probability of being loss-of-function intolerant), pRec (probability of being recessive), and pNull, were obtained using gnomAD v4. pLI, pNull, and pRec are scores related to gene constraints that measure the intolerance of a gene to loss-of-function (LoF) mutations.
Spearman rank correlation coefficients were calculated to assess the relationships between the features. To enhance model performance and ensure stability, the features were normalized, and missing values were imputed. A summary of the features and their corresponding missing values is provided in Table S2.
Model development and interpretabilityFive ML algorithms were applied and compared for modeling: tree-based gradient boosting algorithms XGBoost (eXtreme Gradient Boosting) (Chen and Guestrin 2016), LightGBM (Light Gradient Boosting Machine)(Ke et al. 2017), CatBoost (Prokhorenkova et al. 2018), as well as the deep learning based TabNet (Arik and Pfister 2021), and DNN (Deep Neural Network) (Montavon et al. 2018).
To fine-tune the models with more generalizability and prevent overfitting, the hyperparameter values of each algorithm were optimized using ten-fold cross-validation (CV) over the training dataset. Hyperparameter optimization was conducted using the Bayesian optimization library, called Optuna (Akiba et al. 2019). This is a framework created to automate and accelerate hyperparameter optimization experiments and continually calls for and assesses the objective function for various parameter values to arrive at the best. In this study, a Tree-Structured Parzen Estimator Sampler (TPESampler) was used to explore the hyperparameter space efficiently. This approach often enables faster identification of optimal hyperparameters compared to grid search, which systematically evaluates all combinations within a predefined grid. Moreover, Optuna supports flexible and complex search spaces, including conditional hyperparameter spaces where the configuration of one hyperparameter depends on the value of another. For each ML algorithm, 100 Bayesian optimization trials were performed to determine the hyperparameters that maximize the AUC. Additionally, the optimization process was enhanced by integrating the Median Pruner to eliminate unpromising trials. The specific details for each ML algorithm, including parameter settings and search space ranges, are listed in Table S3.
To interpret the feature importance of the model, the SHAP (Shapley additive explanations) framework was applied to the models. SHAP provides a model-agnostic approach for interpreting machine learning models by attributing a prediction to the contributions of individual features (Lundberg 2017). It is based on coalitional game theory and Shapley values, providing strong theoretical foundations. It is a local explainability model based on Shapley values. The Shapley value is the average marginal contribution of a feature value across all possible coalitions.
Model performance evaluation and other prediction tools comparisonTo assess the generalizability and superiority of the model performance, three test datasets were used and compared with twenty other prediction tools. The precalculated scores of these tools were obtained from dbNSFP v4.4a (Liu et al. 2020), which includes CADD (Rentzsch et al. 2019), ClinPred (Alirezaie et al. 2018), DEOGEN2 (Raimondi et al. 2017), FATHMM (Shihab et al. 2013), gMVP (Zhang et al. 2022), LIST-S2 (Malhis et al. 2020), M-CAP (Jagadeesh et al. 2016), MetaLR (Dong et al. 2015), MetaRNN (Li et al. 2022), MetaSVM (Dong et al. 2015), MutationAssessor (Reva et al. 2011), MutPred (Li et al. 2009), MVP (Qi et al. 2021), Polyphen2(Hvar) (Adzhubei et al. 2010), PrimateAI (Sundaram et al. 2018), PROVEAN (Choi et al. 2012), REVEL (Ioannidis et al. 2016), SIFT (Ng and Henikoff 2003), VARITY (Wu et al. 2021), VEST4 (Carter et al. 2013). These tools used conservation properties as a foundation for model development and incorporated various combinations of other prediction scores, frequency, functional annotations, structural properties, interactions, domain information, epigenomic features, and other properties as features. CADD, ClinPred, DEOGEN2, M-CAP, MetaLR, MetaRNN, MetaSVM, MutPred, MVP, REVEL, and VARITY incorporated other prediction scores or AF as features, which were known to enhance predictive performance. Tools such as CADD and VEST4, which were designed to predict pathogenic variants in both coding and non-coding regions, also incorporated epigenomic properties. Among the twenty tools, tree-based algorithms such as ClinPred, DEOGEN2, M-CAP, MutPred, REVEL, VEST4, and VARITY were the most commonly used. Additionally, DNN-based algorithms including gMVP, MetaRNN, MVP, and PrimateAI, as well as probabilistic-based algorithms like FATHMM, LIST-S2, MutationAssessor, PROVEAN, and SIFT, were also employed. Furthermore, M-CAP, MetaRNN, MVP, REVEL, VARITY, and gMVP were specifically designed to predict the pathogenicity of rare variants. The thresholds for each prediction tool were based on the dbNSFP or were set as recommended in the original studies.
The eight performance metrics used to evaluate the classification performance of the model included accuracy, precision, sensitivity, specificity, F1-score, Matthews correlation coefficient (MCC), area under the receiver operating characteristic curve (AUC), and area under the precision-recall curve (AUPRC). MCC represents the correlation coefficient between the observed and predicted classifications (Vihinen 2012), and can be measured using the following equation:
$$\:\text\text\text\text\text\text\text\text=\:\frac\text+\text\text}\text\:+\text\text+\text\text+\text\text}$$
$$\:\text\text\text\text\text\text\text\text\text=\:\frac\text}\text+\text\text}$$
$$\:\text\text\text\text\text\text\:(=\text\text\text\text\text\text\text\text\text\text\text)=\:\frac\text}\text+\text\text}$$
$$\:\text\text\text\text\text\text\text\text\text\text\text=\:\frac\text}\text+\text\text}$$
$$\:\text1\:\text\text\text\text\text=2\times\:\frac\text\text\text\text\text\text\text\text\:\times\:\text\text\text\text\text\text\text\text\text\text\text}\text\text\text\text\text\text\text\text+\text\text\text\text\text\text\text\text\text\text\text}$$
$$\:\text\text\text=\:\frac\text\times\:\text\text\right)-\left(\text\text\times\:\text\text\right)}\text+\text\text\right)\left(\text\text+\text\text\right)\left(\text\text+\text\text\right)\left(\text\text+\text\text\right)}}$$
where TP, FP, TN, and FN represent true positive, false positive, true negative, and false negative, respectively. The AUC and AUPRC represent the aggregated classification performance across all possible thresholds. The best model was selected based on the highest AUC.
Comments (0)