Study population
We used data from The Maastricht Study, a prospective cohort study enriched with individuals with type 2 diabetes [24]. In brief, this study focuses on the aetiology, pathophysiology, complications and comorbidities of type 2 diabetes and is characterised by an extensive phenotyping approach. Eligible for participation were all individuals aged between 40 and 75 years and living in (and in the surrounding areas of) Maastricht, the Netherlands. Participants were recruited through mass media campaigns, the municipal registries and the regional Diabetes Patient Registry via mailings. Recruitment was stratified according to known type 2 diabetes status, with an oversampling of individuals with type 2 diabetes. The present study includes data from participants who completed the baseline measurements from November 2010 until October 2020 and had undergone valid MRI measurements of the liver (n=5021 participants). Of these, 1004 (19.9%) had missing data on genotyping, resulting in a study population of 4017 participants. We further excluded 78 (1.5%) participants with implausible energy intake (men: <3.3 MJ (800 kcal) or >17.6 MJ (4200 kcal) per day; women: <2.1 MJ (500 kcal) or >14.6 MJ (3500 kcal) per day) and 129 (2.5%) participants with missing data on alcohol intake, resulting in a final study population of 3810 participants (See Electronic supplementary material [ESM] Fig. 1). Missing data were not imputed. The Maastricht study has been approved by the institutional medical ethics committee (NL31329.068.10) and the Minister of Health, Welfare and Sport of the Netherlands (permit 131088-105234-PG). All participants gave written informed consent.
Assessment of IHL content
IHL content was assessed through Dixon MRI using a 3.0 Tesla MRI system (MAGNETOM Prismafit, Siemens Healthineers, Erlangen, Germany) with body matrix and supine radiofrequency coils, as described in detail elsewhere [25].
This method was validated and calibrated against proton magnetic resonance spectroscopy (1H-MRS), the gold standard to non-invasively quantify IHL content, in 36 participants. After calibration, the intra-class correlation coefficient between Dixon MRI and 1H-MRS was 0.989 (95% CI 0.979, 0.994) [25].
Steatotic liver disease was defined by the presence of hepatic steatosis with an IHL content ≥5.56% [26]. The cutoff value for IHL content, originally expressed as CH2 (H2O + CH2), corresponds to 5.89% when IHL content is expressed as CH2/H2O, as was done in the current study [14].
PRS for triglyceride clearance
Genotyping was done with the use of the Illumina Global Screening Array BeadChip (Infinium iSelect 24×1 HTS Custom BeadChip Kit) at the Human Genotyping Facility of the Genetic Laboratory of the Department of Internal Medicine at Erasmus MC Rotterdam, the Netherlands. Details concerning the processes of quality control and imputation are described in detail elsewhere [27].
Genetic variants associated with triglyceride clearance were retrieved from a large-scale genome-wide association study (GWAS) for serum lipids among 312,571 participants of various ethnicities [28]. This study reported 151 SNPs associated with serum triglycerides (p<5 × 10−8) after adjustment for age, sex and the first ten principal components of ancestry. Among them, nine SNPs were excluded due to being monoallelic in Europeans. Based on GeneCards and PubMed searches, the remaining 142 genes were subsequently categorised as: (1) involved in triglyceride clearance only (n=9); (2) involved in triglyceride production only (n=12); (3) involved in triglyceride production and clearance (n=5); (4) uncertain function (n=8); and (5) no results (n=108) (ESM Table 1, ESM Methods). We used the genes in the first group for our primary analyses. To ensure the efficiency of the PRS, several criteria were applied to filter out redundant variants: (1) SNPs with a minor allele frequency lower than 0.01; (2) SNPs in linkage disequilibrium (LD; r2≥0.1); (3) mismatching SNPs (e.g. a SNP with A/C in the previous GWAS and G/T in The Maastricht Study); (4) SNPs with low imputation quality (imputation score [INFO] <0.8). The nine SNPs were all eligible for this study and are presented in Table 1.
Table 1 List of serum triglyceride-associated genes involved in triglyceride clearance only
The PRS for triglyceride clearance was calculated by multiplying the dosage of effect allele for each SNP by its corresponding weight (effect size) and then summing all variants together. The effect size for each variant was derived from the previous GWAS [28] (ESM Methods). Effect allele dosage of a SNP for each participant was coded as 0, 1 and 2 for non-carriers, heterozygous carriers and homozygous carriers, respectively. For imputed data, genotype dosage data were converted to best guess genotypes based on a minimum genotype probability of p>0.8 [27].
Measurement of serum triglycerides
Blood was drawn after an overnight fast. Serum triglycerides were measured by use of an automatic analyser (Beckman Synchron LX20, Beckman Coulter, Brea, USA) in venous blood samples. A detailed description of protocols for the laboratory assessments has been reported elsewhere [24]. Hypertriglyceridaemia was defined as serum triglycerides ≥2.3 mmol/l [29].
Diagnosis of CVD at baseline and during follow-up
CVD status was assessed using a self-reported questionnaire both at baseline and annually during follow-up over 10 years [24]. CVD was defined as: (1) myocardial infarction; (2) cerebrovascular infarction and/or haemorrhage; (3) percutaneous artery angioplasty or vascular surgery of the coronary, abdominal, peripheral or carotid arteries. Of the 3301 participants free from CVD at baseline, 3217 had valid annual follow-up data on incident CVD (ESM Fig. 2).
Covariates and other variables
Age, sex, education status (low, medium, high) and smoking status (never, former or current smoker) were assessed from questionnaires [24]. Alcohol consumption was assessed by a tailor-made food frequency questionnaire (FFQ) [30]. Medication use was assessed during medication interviews. Blood pressure was measured as the mean of at least three blood pressure readings (Omron 705IT, Japan).
Participants underwent a standardised 2 h 75 g OGTT after an overnight fast to determine glucose metabolism status (GMS), which was defined according to the World Health Organization 2006 criteria as normal glucose metabolism (NGM), impaired fasting glucose and impaired glucose tolerance (combined as prediabetes) or type 2 diabetes [31]. For safety reasons, participants using insulin or with a fasting glucose level >11.0 mmol/l (determined by finger prick) did not undergo the OGTT. These individuals were automatically classified as having diabetes. HbA1c, insulin and lipid profiles were measured in venous fasting blood samples, as previously described [24]. Insulin resistance was assessed by the HOMA-IR, which was calculated with the HOMA calculator version 2.2.3 for Windows (www.OCDEM.ox.ac.uk).
Statistical analysis
Continuous data are presented as mean ± SD, or as median (interquartile range) in the case of non-normal distribution. Categorical data are presented as number (%).
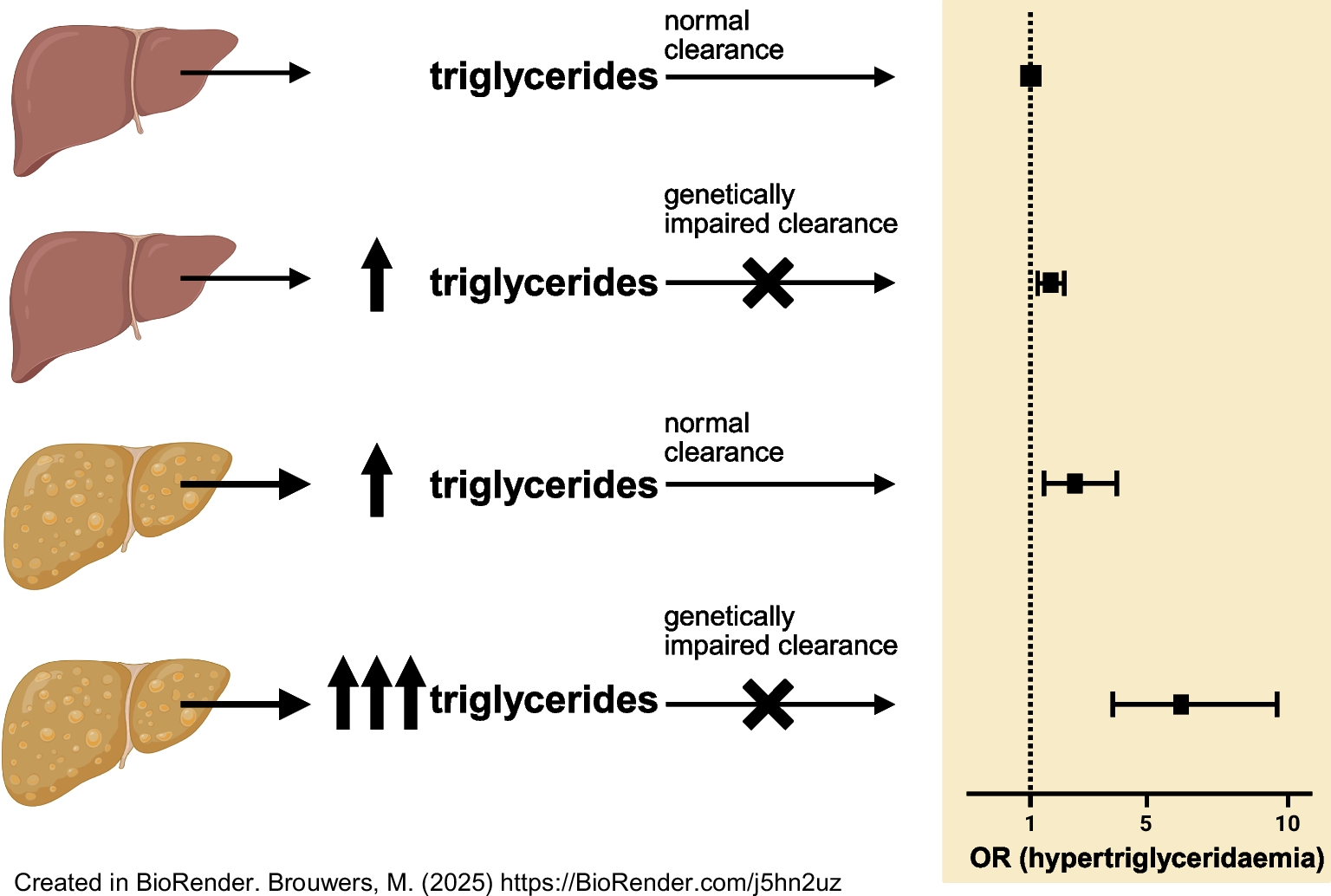
First, to examine the effect of cross-sectional interaction between IHL content and the PRS for triglyceride clearance on serum triglycerides, we performed multivariable linear regression analysis as the primary analysis. IHL content, the PRS for triglyceride clearance and the interaction term IHL content × PRS for triglyceride clearance were used as exposures, and (log10) serum triglycerides was used as the main outcome. To obtain interpretable results, we back-transformed the regression coefficients, which should be interpreted as the fold change in serum triglycerides that is associated with a 1 unit increase in IHL content or PRS [14]. The following regression models were used for the analyses: model 1: crude model; model 2: with adjustment for age, sex, type 2 diabetes (because of the oversampling of type 2 diabetes in The Maastricht Study), MRI lag time (i.e. the time between the basic measurements and the MRI measurement of the liver, included as the interaction term ‘IHL content × MRI lag time’) and the first ten principal components of population stratification; model 3: with additional adjustment for lipid-modifying medication and alcohol intake.
Second, we classified the participants into six groups according to steatosis status (binary, yes/no) and PRS for triglyceride clearance (in tertiles, low/intermediate/high) to study the effect of interaction on risk of hypertriglyceridaemia in a multiple logistic regression analysis.
Several sensitivity analyses were performed. We repeated the analyses after: (1) stratification by sex; (2) stratification by type 2 diabetes status; (3) stratification by lipid modification; (4) replacement of IHL content by HOMA-IR.
All analyses were also repeated after replacing the PRS for triglyceride clearance by a PRS for triglyceride genes involved in ‘triglyceride production only’ (n=12), and a PRS involving nine triglyceride genes randomly selected from all 142 genes (ESM Methods, ESM Table 1). For the latter, we selected 500 sets of nine triglyceride genes at random from all genes, and then generated the mean value, a null distribution, of the interaction term IHL content × PRS and its CI using bootstrapping (Nbootstrapping=5000).
Finally, we performed an exploratory analysis to study the impact of longitudinal interaction between IHL content/steatotic liver disease and PRS for triglyceride clearance on incident CVD risk using Cox proportional hazards regression analysis. The following models were applied: model 1: crude model; model 2: after adjustment for age, sex, type 2 diabetes, IHL content/steatosis × MRI lag time and the first ten principal components of population stratification; model 3: after additional adjustment for smoking status, alcohol intake, lipid-modifying medication, anti-hypertensive medication, systolic blood pressure and LDL-cholesterol.
The percentage of missing values for covariates was less than 1.1%, except for HOMA-IR (58.1% missing). The missing data were not imputed and were left as missing in all of the analyses. Statistical analyses were performed with the use of R statistical software version 4.0.1 (the R statistical software is available from https://cran.r-project.org/bin/windows/base/old/4.0.1/).



Comments (0)