
Remember me
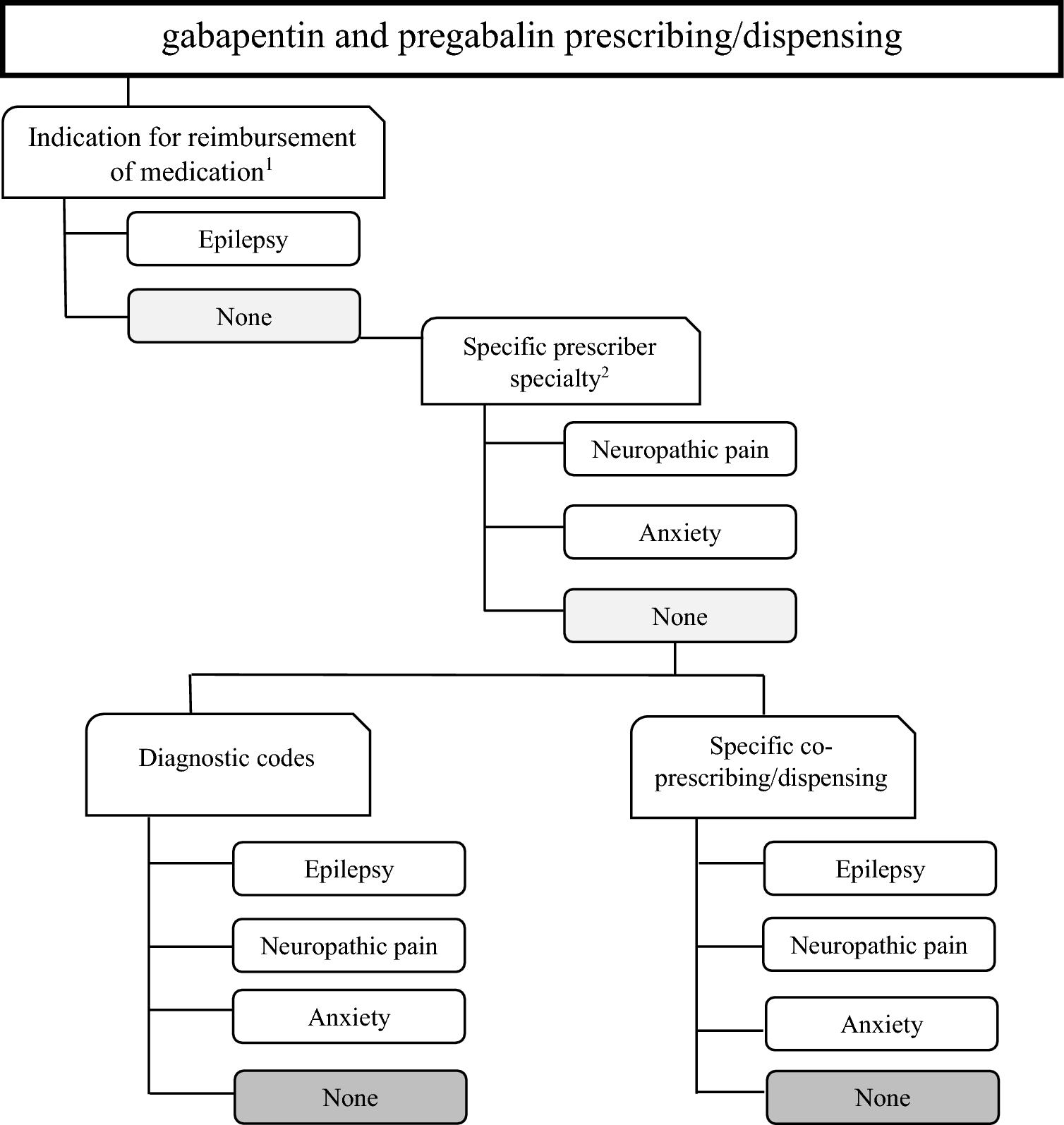
In total, 26 codes completed the survey (79% of the total study population), one of whom did not indicate their educational background. The participation rate per institution was 100% (5/5) for NIPH, 75% (6/8) for NOMA, and 75% (15/20) for RELIS. An overview of the participant demographics is presented in Table 3.
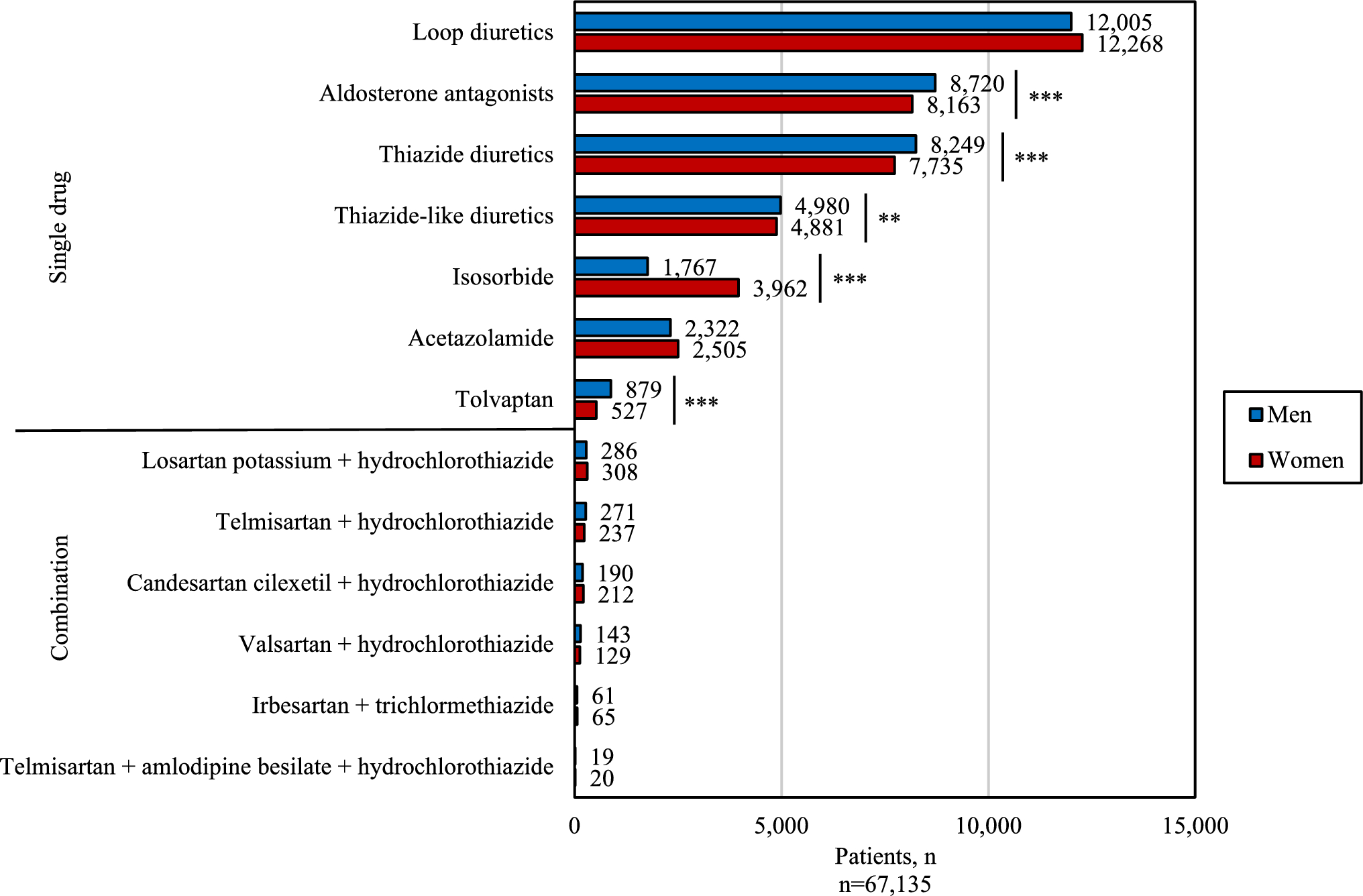
Table 3 Demographic overview of the survey participantsThe level of coding consistency among participants, the level of consistency with the standard PT selection, and the number of answers with low perceived difficulty per task are shown in Fig. 2. In the figure, the sequence of the tasks is reorganized in ascending order of low perceived difficulty. The data in Fig. 2 show that, as expected, all the answers to the baseline task were identical to the standard. For the other tasks, the answers containing the complete standard PT selection (with or without addition) ranged from a maximum of 25 (task 12) to a minimum of 2 (task 6). For 8 of 11 tasks, the largest agreement corresponded to the standard PT selection. Interestingly, task 3 had the third largest maximum agreement (15 answers) but no answer containing the standard PT selection. The lowest agreement was recorded in task 10 (three answers), which, by contrast, had the lowest perceived difficulty. Also, task 2 had the same perceived difficulty as the baseline but scored low, both for answers containing the standard PT selection (three answers) and for the size of the largest agreement (five answers). Hence, the data suggest that the perceived difficulty did match the coding performance in our selection of tasks.
Fig. 2
Clustered column chart of the number of answers identical to the standard preferred term (PT) selection (blue), the number of answers containing a complete standard PT selection and one or more additional PT(s) (orange), the maximum number of identical answers (grey), and the number of answers in which the participants evaluated the task at a difficulty level 1 or 2 in a scale from 1 (easy) to 4 (very difficult) (yellow). The task sequence is in descending order of percentage of perceived difficulty. Note that, in tasks 1, 4, 5, 8, 9, 10, 11, and 12, the answers with the largest agreement corresponded to the standard PT selection
Table 4 shows the categorization of coding omissions into answers containing no substituting PTs, answers containing both standard PTs and substituting PTs, and answers containing only substituting PTs. The latter category represented the only possible deviation for tasks with one PT in the standard PT selection. Among these, the standard PT in task 4 (procedural hypotension) was substituted by 12 participants, whereas the standard PT in task 12 (clear cell renal cell carcinoma) was substituted by only one participant. However, for task 12, it is worth noting that, although the selected PT was consistent in 25 cases, only 16 of the participants captured the additional information “metastatic carcinoma,” something that is possible to observe only at the LLT level and therefore not visible in our quantification.
Table 4 Survey tasks grouped per number of preferred terms (PTs) in the standard selectionIt was generally more common for coders to substitute a part of the standard PTs in tasks in which the standard PT selection contained three, four, or five PTs than it was for tasks with only one PT in the standard PT selection. However, the data show no clear increasing or decreasing trend. For instance, in task 2, which contains five PTs in the standard PT selection, coders commonly omitted one PT among “somnolence, fatigue, asthenia” without substituting it. Further, in task 6, which contained four PTs in the standard selections, only one of 24 participants who did not code the information regarding fall and head injury chose a substituting PT. In our selection of tasks, heterogeneity did not seem to be affected by the number of verbatims, rather by the type of information in the verbatim.
Of a total 286 survey tasks answered by the 26 participants, 103 (36%) were identical to the standard PT selection. Figure 3 shows the distribution of the remaining 183 survey answers, which were inconsistent with the standard PT selection, into the different types of identified inconsistencies, as well as the cumulative impact of each type of inconsistency. The most frequent deviation from the standard PT selection was omission(s) and use of one substituting PT (88 answers), followed by omission(s) without any substitution (53 answers). Together, these accounted for 75% of coding inconsistencies.
Fig. 3
Pareto chart illustrating the distribution of the 183 survey answers deviating from the standard preferred term (PT) selection (bars) and cumulative impact of each type of coding inconsistencies identified (line)
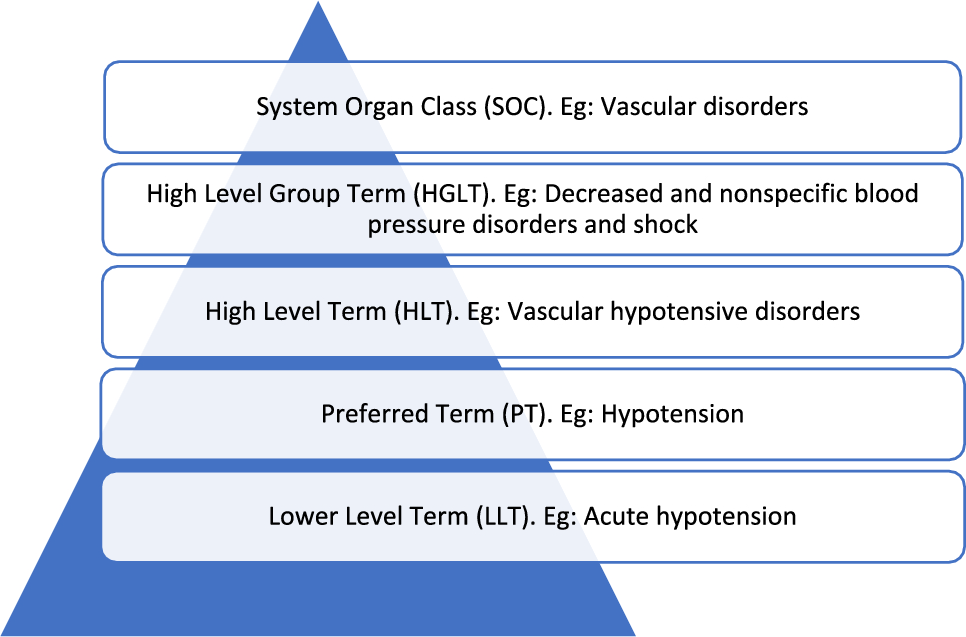
As an indication of the potential impact of each substitution in subsequent data mining of the registry, we report all the substitutions with respective classifications into three levels of impact (Table 5). Overall, of the 32 unique PTs in the standard PT selection, 21 (65.6%) were substituted at least once, resulting in 48 unique substitutions and a total of 152 substituted PTs. Of these, 100 (65.8%) were substituted with a PT that led to the same common HLT (i.e. “Hypotension” instead of “procedural hypotension”), 36 (23.7%) were substituted by a PT that led to a different HLT but to a common SOC (i.e. “teratogenicity” instead of “maternal drugs affecting fetus”), and 16 (10.5%) were substituted by a PT that led to a different SOC. Examples of substitutions leading to different SOCs were coding for diagnoses (i.e. “thyroiditis” instead of “hypometabolism,” “angioedema” instead of “peripheral swelling,” “thrombocytopenia” instead of “platelet count decreased”), coding for investigations (i.e. “prenatal screening test abnormal” instead of “foetal cardiac disorder”), or coding for different information (i.e. “aborted pregnancy” instead of “abortion induced”). The maximum variability in substituting terms was six (see Table 5, “procedural hypotension” and “fetal cardiac disorder”).
Table 5 The table shows the standard PTs that were substituted in the survey answers (column 1) and relative substituting PTs (column 2)3.2 Focus Group ResultsEight participants (31%) took part in the focus group interviews (Table 6). For a summary of themes, subthemes, and representative citations, see Table 3 in the ESM. Here, we summarize the content of each theme.
Table 6 Description of the focus groups3.2.1 Theme 1: Aspects Related to Information ProcessingFocus group participants referred to several aspects, or elements, needed to process the information described in the verbatim and classify it using MedDRA®.
One aspect was that when information was long and complex, the coder needed to determine its essence in order to assign the most appropriate MedDRA® term. This was described as challenging and sometimes required selection of multiple terms. Participants noted that, in their normal practice, it is common to use free narrative to include information that was not captured with MedDRA®.
A related aspect of information processing was categorizing the verbatims as “adverse event”, “underlying condition”, “indication”, or even “product” with the use of a drug dictionary (such as for the information on alcohol consumption, migraine prophylaxis, or intrauterine contraception). In their discussions, participants reasoned around the possible categorization in parallel with reasoning around the most appropriate term to select. They referred to categorization as an integral part of the coding task, as it helped with “sorting out” and identifying the information that was most relevant to describe the events. Sometimes, when trying to clarify the chain of events, and to distinguish an event from its consequences, participants tried to come to an agreement about how different pieces of information should be classified. When the correct classification was unclear, coders used individual evaluation. Also in this case, the strategies of multiple classifications (information can be categorized in multiple categories) and unstructured text (information that is difficult to categorize can be added as unstructured text) could be used, according to participants.
A further aspect of information processing was that lay language, common in patient reports, needed to be correctly interpreted and classified using MedDRA® terms. The perceived difficulties here were the lack of a systematic strategy and a solution that can be considered the preferred one. However, participants pointed out that not only lay language but also medical language needed to be interpreted, especially because translation from Norwegian to English is necessary. LLTs were described as very similar to each other, so finding a match in the Norwegian verbatim was potentially challenging, especially for events that the coder encountered infrequently. Dermatological symptoms were unanimously reported as particularly difficult to code.
Finally, language is processed via culture-specific interpretation. In some cases, when told that their term choice differed from the standard PT selection proposed by the authors, participants stated that they made the choice that is correct considering the common use of the term in the Norwegian language. For instance, a participant stated that “water in the body is the Norwegian way to express ‘oedema’”. Similarly, participants pointed out that the Norwegian expression “lavt stoffskifte” (literally “low metabolism”) is used specifically to indicate low thyroid function among Norwegian health professionals and patients.
3.2.2 Theme 2: Ambiguity Resolution StrategiesParticipants adopted some strategies to address ambiguous information. When facing vague descriptions, some selected a general term to avoid over-interpretation. Another strategy was to code multiple terms, with the aim of giving more options when unsure about which of many terms matches the described information.
Opinions varied as to whether coding information reported as uncertain was correct. Some participants thought that when information was stated as “uncertain,” it should not be coded. Others argued that, since the information they dealt with was uncertain by nature, all information should be coded and, if necessary, amended. Their main concern was missing important information.
3.2.3 Theme 3: Contextual Thinking and Causal ReasoningCoders reported that their duties included causality assessment between the adverse events and suspected medicinal product. Some indicated that they bore this in mind throughout the selection of the MedDRA® term, using it to guide what they deemed to be the most appropriate selection. Some participants also regarded information deemed relevant to causality assessment as justifiably eligible for coding, irrespective of its certainty; for instance, if it could provide a possible alternative explanation for the described symptom.
Some of the participants expressed that the coding tasks were sometimes more difficult than real-life tasks because the suspected medicine was unknown. Some agreed that knowing the suspected medicine(s) could guide the choice of whether to code uncertain information. In particular, some accounted for the pharmacological mechanism when determining which information to code and which to omit. For example, in task 6, a centrally acting medicinal product, but not an anticoagulant, would have led some to code “head injury”. Others disagreed and insisted that coding should have been the same, irrespective of the suspected medicine. In addition to the lack of suspected medicine, participants thought that, in general, lack of contextual information undermined contextual thinking, making it difficult to select the best-fitting MedDRA® term.
3.2.4 Theme 4: External ResourcesParticipants named several resources they used when they lacked contextual information. The most immediate and low-threshold daily practice was consultation with peers. Outside the survey, consultations with medical doctors occurred when coders were unfamiliar with verbatims or when the verbatims did not match with MedDRA® terms. In these cases, participants also reported using Google searches. Another point of contact for coders could have been the original reporters when the verbatims were insufficient or vague. Such contacts were described as contingent on a case-by-case evaluation according to the seriousness of the reported event(s), time constraints, and overall report quality. Some noted that, when the report was very poorly described, contacting the reporter did not yield better information. Participants also spoke of MedDRA® resources that were routinely used for MedDRA® term selection. For instance, informants actively used the MedDRA® hierarchy and assessed which concept the term belonged to in the higher levels of the hierarchy. In addition, all participants said they were familiar with the MTS:PTC guideline. However, they reported performing situational evaluations on the applicability of guidelines to certain ambiguous verbatims. For instance, one participant who was aware that item 3.2 of the MTS:PTC prescribes the coding of provisional diagnoses declared that it could not apply to extremely uncertain tasks, such as N6.
3.2.5 Theme 5: Wish for Systematic Training that Includes an Overview of Pharmacovigilance Activities Downstream CodingParticipants reported that MedDRA® training was unsystematic. Some felt that they started the job with insufficient training and were eventually introduced to a structured MedDRA® Maintenance and Support Services Organization course. All participants considered such a course as very useful, and some reported having gained a whole new understanding of the coding task after the course. Participants wished for a more systematic and periodical training offer to refresh and update their knowledge. They reported that adequate training would stress the importance of coding to the whole downstream process of signal detection and analysis of signals. With this awareness, the coder would be motivated to capture the relevant information as accurately as possible, rather than seeing coding as a mere bureaucratic duty. Some participants proposed that a way to foster the role of the coder within the whole pharmacovigilance process would be to collaborate with other institutions for different tasks. For instance, during the COVID-19 vaccination campaign, meetings were held between coders and assessors to discuss signals, and collaborative coding efforts were undertaken for large numbers of reports.
3.3 Integrated ResultsBy summarizing and integrating survey and interview data, we highlight the main findings indicated in Table 7.
Table 7 Integrated overview of the main findings from the two study phases
Comments (0)