4.1 Overall Performance
This comprehensive evaluation of the algorithm for identifying pregnancy cases in VigiBase shows a robust performance and highlights aspects of the algorithm that enabled correct identification of reports, and where potential improvements could be made. It also provides insights into the reporting of pregnancy exposure information in case reports and demonstrates the influence of report exchange formats and coding practices in a global setting.
In our analysis, the algorithm successfully flagged 75% of the reports manually annotated as pregnancy cases. Among the pregnancy cases undetected by the algorithm, the majority were attributed to preprocessing issues arising from reporting formats or terminologies other than E2B and MedDRA®, particularly relating to unmapped indications reported in non-English text. Restricting the analysis to E2B reports substantially increased the recall to 91%. For these reports, the primary reason for false negatives was the failure to detect reports containing pregnancy information exclusively reported in free-text fields, owing to the algorithm’s inability to process such fields. Reports were also missed because of incompleteness of information, such as the lack of explicit pregnancy-specific information, or the existence of explicit, yet sparse, pregnancy details.
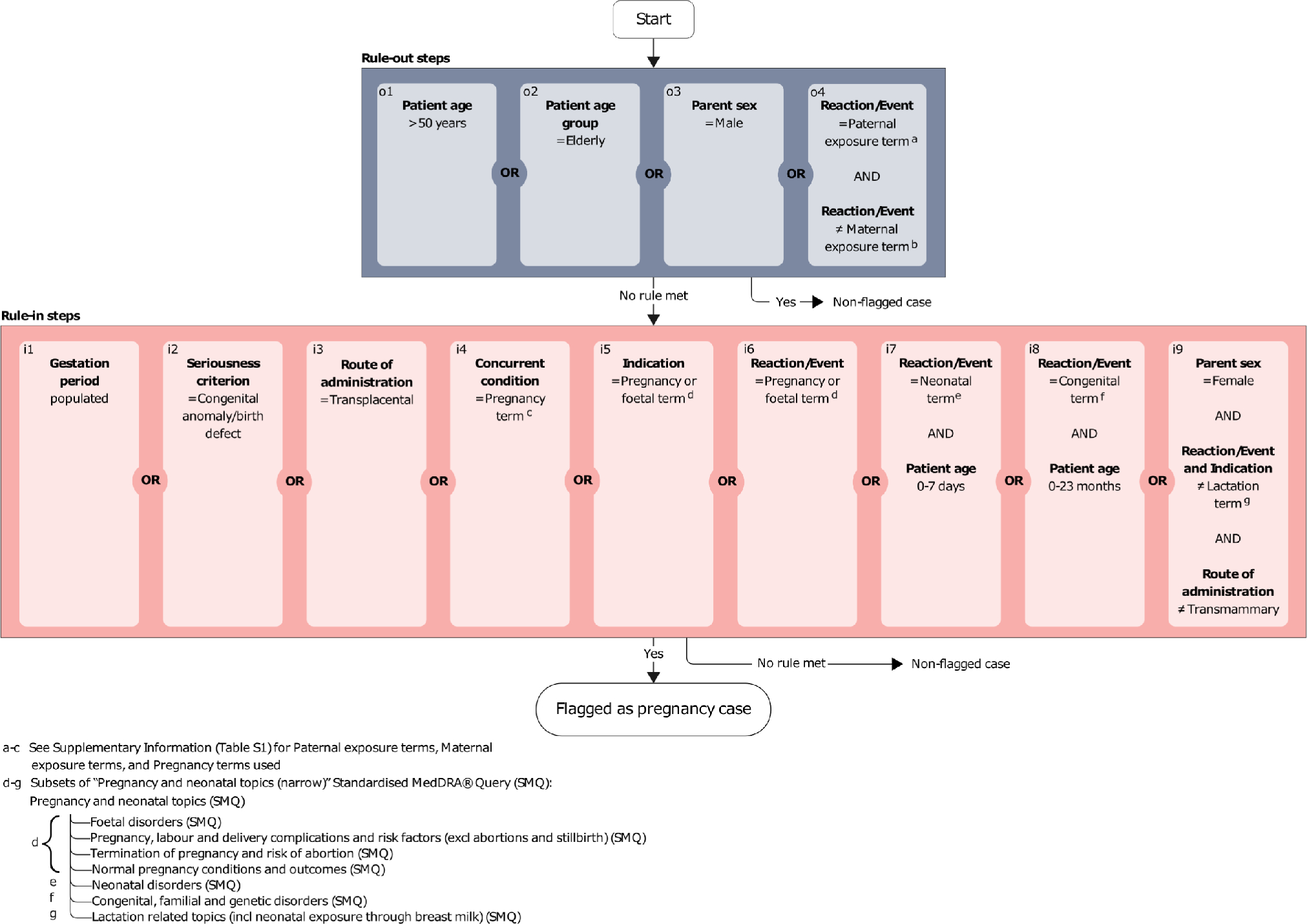
The age thresholds for ruling in reports with neonatal and congenital events were implemented to allow for capturing additional relevant cases not detected through the other rules, while avoiding the erroneous flagging of cases with pre-existing congenital events or postnatal exposures. A few cases, mostly older non-E2B reports, were inadvertently missed because of these age restrictions as the patient age referred to the pregnant person or was missing. However, this cautious approach was essential to protect against numerous incorrect classifications as evidenced in our precision analysis. These age conditions, along with the ruling out of patients aged over 50 years, were the main contributors to the algorithm’s relatively higher precision compared with the pregnancy SMQ.
Most of the cases mistakenly flagged as pregnancy cases by the algorithm included post-partum indications and adverse events that were included in the pregnancy SMQ but that were not specific to pregnancy. Miscoding of pregnancy-related information as a source of false positives was spread over several different data elements and did not indicate one specific underlying issue.
4.2 Baseline Comparison
The “Pregnancy and neonatal topics (narrow)” SMQ was chosen as the baseline method to benchmark the performance of the algorithm. This was the method applied in several studies for retrieving pregnancy cases [13,14,15, 21, 27,28,29,30, 33] and it was the comparator used for evaluation of the algorithm developed in EudraVigilance [33]. We note that the intention of our study was not to compare the performance of the algorithm with the SMQ to decide which method is better, but to understand where they perform differently and that they may be used in different scenarios. The SMQ plays an important role in the algorithm and is the main contributor to the high recall. Also it should be noted that the comparison is restricted to coded adverse events for the SMQ. With this in mind, the algorithm captured more pregnancy cases than the SMQ and did so more precisely. The few cases that the SMQ correctly captured but the algorithm missed were primarily older non-E2B reports, captured by the SMQ because it did not apply age conditions for congenital and neonatal events. However, for the same reason, this led to more false positives for the SMQ, resulting in a significantly lower precision.
4.3 Evaluation Approach
To ensure a rigorous evaluation, we established large annotated datasets, enhancing data diversity and coverage of potential pregnancy-related scenarios. Four experienced annotators, each contributing to a large volume of annotations, adhered to a guideline that provided instructions to follow during the annotation process. Two of the annotators had been involved in developing the algorithm, hence we included two additional assessors to ensure annotation robustness. The annotated data showed high inter-annotator agreement, indicating consistent and reliable annotations.
The annotations were based only on the reported information available in VigiBase, which sometimes, because of incomplete data, limited the ability to reach definite conclusions about a pregnancy exposure. Given also that narrative information is not shared with VigiBase for all reports, it is plausible that cases with pregnancy-related information confined to the narrative were not correctly annotated as pregnancy cases. Consequently, we may have underestimated the true number of pregnancy-related reports in VigiBase.
The primary challenge in this study was estimating recall, given that most reports in VigiBase do not pertain to pregnancy. Annotating a random sample from the entire database would have demanded an unreasonable amount of resources to identify enough pregnancy cases for the required statistical power. To address this, our strategy for creating the dataset to estimate recall excluded reports less likely to be pregnancy related, thus increasing the prevalence of pregnancy cases in our sample. This allowed us to annotate the number of pregnancy reports required, while being able to demonstrate the use of the algorithm in a dataset that is sufficiently representative to be applicable to the whole of VigiBase. Consequently however, we could not directly evaluate the implications of the algorithm ruling out certain individuals, specifically patients aged over 50 years, as these were already excluded from the Downsampled dataset. Nevertheless, the comparison with the SMQ output in the Random dataset suggested that ruling out cases based on age is an effective strategy for enhancing precision without compromising recall.
To assess the algorithm’s ability to identify pregnancy cases within all of VigiBase, we intentionally refrained from imposing any restrictions on the time of reporting or the reporting formats of the test data. Hence, the reports included in the evaluation dated back to the 1970s and represented different reporting formats and practices that may have changed over the years. Our analysis showed that the algorithm performs better when applied to reports submitted in the E2B format. Not only is the E2B format more extensive and able to accommodate additional information, including data related to pregnancy, compared with other formats like the International Drug Information System - INTDIS, reports in the E2B format are also more likely to comply with current international standards for coding and reporting. While this increases the potential for well-documented reports, importantly, it does not necessarily ensure them. Additionally, of note, the algorithm was developed within VigiBase, which conforms to the E2B(R2) standard, hence, the rules were based on this data model, naturally favouring this type of report.
4.4 Applicability
The applicability of the VigiBase pregnancy algorithm is influenced by several factors, including intrinsic factors such as the exclusion of patients aged over 50 years, and extrinsic factors such as database characteristics related to regional reporting practices. Alternative methods may offer higher precision, making them suitable for studies prioritising precision over recall. These methods could, for example, rely on reported pregnancy exposure terms; importantly, we noted that less than half of the annotated pregnancy cases in our study included such a term. Conversely, if capturing all reports for a certain adverse event is crucial, a specific term search may be more appropriate, especially in studies involving a manual review to exclude false positives. Future studies could explore different applications of the algorithm and compare with other more or less inclusive approaches, to inform decision making.
The precision estimate for the pregnancy algorithm developed in EudraVigilance, which uses the E2B reporting format and MedDRA® terminology, was very similar to that for the VigiBase algorithm. The performance was evaluated on 100 cases retrieved by the EudraVigilance algorithm and resulted in a precision of 90% (95% CI 84–96) [33]. Recall was not evaluated in the study. Importantly, the two approaches somewhat differ in scope: the EudraVigilance algorithm intends to capture only adverse outcomes and includes paternal exposures, the VigiBase algorithm intends to capture all pregnancy exposures regardless of outcome and excludes paternal exposures. Still, the methods are similar and comparing the outputs may inform future developments in this area.
Our study suggests that most of the pregnancy cases in VigiBase refer to the pregnant person while a minority refer to the foetus/prenatally exposed child. Hence, for certain studies focusing on outcomes in the foetus/child, it would be desirable to restrict the analysis to a subset of such reports. As an example, in signal detection, the statistical background is important, and pregnant person reports heavily outnumbering foetus/child reports may risk masking specific patterns in the subgroup of interest. Furthermore, as the algorithm captures both type of reports, applying it with the aim to retrieve a case series on foetal/child outcomes would potentially require manual data cleaning to remove cases referring to the pregnant person and vice versa.
Although the algorithm was initially developed and evaluated in a global database, we expect it to be applicable to other databases conforming to the E2B format and using MedDRA® for coding. The algorithm follows an explainable and transparent rule-based method that would be relatively easy to replicate in other databases and adjust to local requirements. The current evaluation provides insights to manage expectations as the algorithm’s performance may vary across databases because of differences in their structures and regional reporting patterns.
4.5 Future Improvements
While transparency is crucial for understanding algorithm outputs and is a key strength of rule-based methods, incorporating additional report data, such as the case narrative, and using more advanced methods, like large language models, could enhance the identification of pregnancy cases, though potentially trading off transparency, reproducibility and reliability. An additional rule-based feature would be to use the age group “Foetus”, which was introduced in the E2B(R3) format. This feature was not explored as the VigiBase cohered to the E2B(R2) data model at the time the algorithm was developed. The E2B(R3) format also introduced an opportunity to extend it with additional data elements. If used in a standardised way, this could be an option for transferring a database-specific pregnancy flag. Our study also suggests that medicinal products indicated solely for use during pregnancy could provide a means for capturing exposures during pregnancy. However, regional differences and maintenance requirements limit the feasibility, at least for a global application. Investigating the potential to distinguish between reports referring to the pregnant person and the foetus/child, as well as exploring separate algorithms for detecting reports related to paternal or lactation exposures, may enhance data precision and broaden the scope of pregnancy-related investigations.
Given the findings of this study, the most crucial step for effectively retrieving pregnancy-related case reports in pharmacovigilance databases would however be to achieve global harmonisation of standards for collecting and exchanging pregnancy data. This would not only facilitate the identification of such case reports but once identified, well documented and dependable reports are key to allow for valid case assessments. The consequence of incomplete information became evident during the annotation process as case reports providing sparse or implicit pregnancy information made it difficult even for a human to determine definitively whether a case was pregnancy related or not. This highlights also the need for improved reporting and coding guidelines, as well as adherence to those that already exist. Encouragingly, recent initiatives within the ConcePTION project have suggested frameworks for data collection to increase the quality of pregnancy data and how to assess the quality of the information in pregnancy-related case reports [11, 12, 40, 41]. In addition to improving frameworks and guidelines, however, it is crucial to implement training efforts that raise awareness about how to report pregnancy information.
In summary, our study highlights the importance of harmonised global standards for reporting pregnancy exposures, and compliance with those that exist, for the retrievability of pregnancy-related case reports. Although the current standard transmission format allows for reporting pregnancy-related information through many different data elements, the necessity for a pregnancy algorithm stems from the absence of a dedicated field to report and, subsequently, retrieve pregnancy exposure cases [11, 12]. While various approaches are currently employed to identify pregnancy-related cases, thorough performance evaluations are notably absent in most studies. This underscores the importance of our study, recognising the performance of the VigiBase pregnancy algorithm in terms of recall and precision, as well as understanding its limitations and potential biases.

Comments (0)